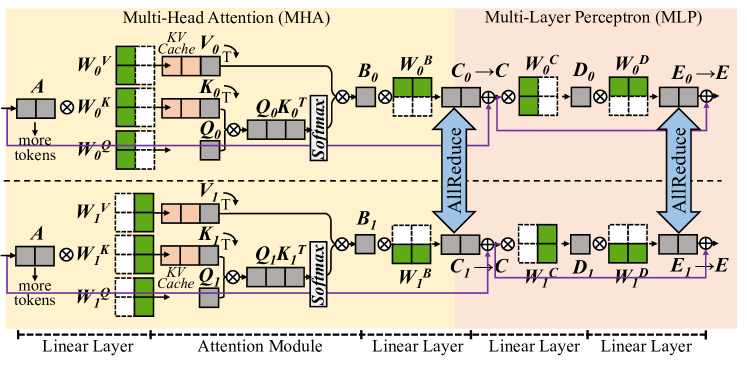
## Diagram: Multi-Head Attention (MHA) and Multi-Layer Perceptron (MLP)
### Overview
The image is a diagram illustrating the architecture and flow of data through a Multi-Head Attention (MHA) module and a Multi-Layer Perceptron (MLP) module. The diagram shows the connections and operations between different layers and components within these modules.
### Components/Axes
* **Titles:**
* Multi-Head Attention (MHA) - Located at the top-left.
* Multi-Layer Perceptron (MLP) - Located at the top-right.
* **Layers:**
* Linear Layer (MHA): Located at the bottom-left, spanning the first section.
* Attention Module (MHA): Located in the middle, spanning the second section.
* Linear Layer (MLP): Located at the bottom-right, spanning the third and fourth sections.
* **Components (MHA):**
* A (Input): Located at the left of the MHA module.
* W0K, W1K (Weight matrices for Key): Located after the input A.
* W0V, W1V (Weight matrices for Value): Located at the top and bottom, respectively.
* W0Q, W1Q (Weight matrices for Query): Located below W0V and W1V, respectively.
* KV Cache: Located next to W0V and W1V.
* K0T, K1T (Transposed Key matrices): Located to the right of the KV Cache.
* Q0, Q1 (Query matrices): Located to the right of W0Q and W1Q, respectively.
* Q0K0T, Q1K1T (Query-Key product): Located to the right of K0T and K1T.
* Softmax: Located to the right of Q0K0T and Q1K1T.
* B0, B1 (Output of Attention Module): Located to the right of Softmax.
* W0B, W1B (Weight matrices): Located to the right of B0 and B1.
* **Components (MLP):**
* C0, C1 (Input to MLP): Located to the right of W0B and W1B.
* W0C, W1C (Weight matrices): Located to the right of C0 and C1.
* D0, D1 (Intermediate output): Located to the right of W0C and W1C.
* W0D, W1D (Weight matrices): Located to the right of D0 and D1.
* E0, E1 (Output before final layer): Located to the right of W0D and W1D.
* E (Final output): Located to the right of E0 and E1.
* **Arrows:** Indicate the direction of data flow.
* **AllReduce:** Blue arrows indicating a reduction operation.
* **Colors:**
* Green: Represents weight matrices (W0V, W1V, W0Q, W1Q, W0B, W1B, W0C, W1C, W0D, W1D).
* Peach: Represents KV Cache and transposed Key matrices (K0T, K1T).
* Gray: Represents other intermediate matrices and operations.
* Purple: Represents the flow of "more tokens".
### Detailed Analysis
* **MHA Module (Top):**
* Input A is multiplied by W0K.
* W0V, W0Q are weight matrices.
* KV Cache stores Key and Value matrices.
* Q0K0T is the product of Query and Transposed Key matrices.
* Softmax is applied to Q0K0T.
* The output of the attention module is B0.
* B0 is multiplied by W0B.
* **MHA Module (Bottom):**
* Input A is multiplied by W1K.
* W1V, W1Q are weight matrices.
* KV Cache stores Key and Value matrices.
* Q1K1T is the product of Query and Transposed Key matrices.
* Softmax is applied to Q1K1T.
* The output of the attention module is B1.
* B1 is multiplied by W1B.
* **MLP Module (Top):**
* C0 is the input to the MLP.
* C0 is multiplied by W0C.
* D0 is the intermediate output.
* D0 is multiplied by W0D.
* E0 is the output before the final layer.
* E0 is added to the output of the AllReduce operation to produce E.
* **MLP Module (Bottom):**
* C1 is the input to the MLP.
* C1 is multiplied by W1C.
* D1 is the intermediate output.
* D1 is multiplied by W1D.
* E1 is the output before the final layer.
* E1 is added to the output of the AllReduce operation to produce E.
* **AllReduce:**
* The AllReduce operation combines the outputs of the two parallel paths in both the MHA and MLP modules.
* The output of the AllReduce operation is added to E0 and E1 to produce the final output E.
* **"more tokens"**:
* A purple arrow indicates the flow of "more tokens" from the input A to the Query matrices (W0Q, W1Q).
### Key Observations
* The diagram illustrates a parallel processing architecture with two identical paths in both the MHA and MLP modules.
* The AllReduce operation is used to combine the outputs of the parallel paths.
* The MHA module consists of a linear layer and an attention module.
* The MLP module consists of multiple linear layers.
### Interpretation
The diagram provides a high-level overview of the architecture and data flow in a Multi-Head Attention (MHA) module and a Multi-Layer Perceptron (MLP) module. The MHA module is used to capture relationships between different parts of the input sequence, while the MLP module is used to perform non-linear transformations on the data. The parallel processing architecture and the AllReduce operation are used to improve the efficiency and scalability of the model. The "more tokens" flow suggests that the query matrices are influenced by additional input tokens, potentially allowing the model to incorporate more contextual information.