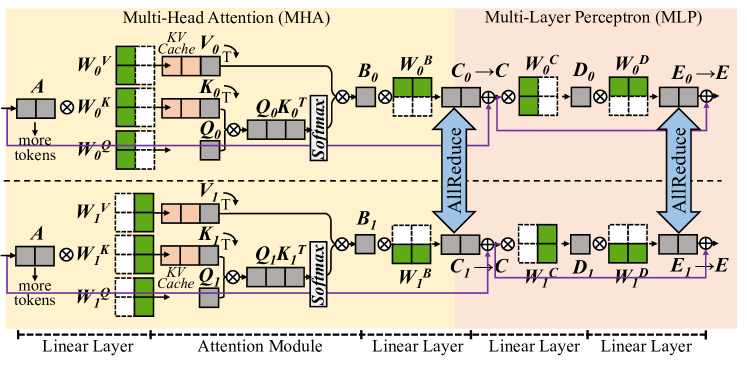
## Diagram: Multi-Head Attention (MHA) and Multi-Layer Perceptron (MLP) Architecture
### Overview
The diagram illustrates a neural network architecture combining **Multi-Head Attention (MHA)** and **Multi-Layer Perceptron (MLP)** components. It shows data flow through linear layers, attention mechanisms, and perceptron layers, with explicit attention to distributed training operations like **AllReduce**.
### Components/Axes
- **Key Elements**:
- **Linear Layers**: Input/output transformations (e.g., `A → W_O^K`, `E_0 → E`).
- **Attention Module**:
- **Queries (Q)**: `Q_O`, `Q_1` (computed via `W_O^Q`, `W_1^Q`).
- **Keys (K)**: `K_O`, `K_1` (computed via `W_O^K`, `W_1^K`).
- **Values (V)**: `V_O`, `V_1` (computed via `W_O^V`, `W_1^V`).
- **Cache**: `K^V` (stores key-value pairs for efficiency).
- **Softmax**: Applied to attention scores.
- **MLP Layers**:
- **Bias Terms**: `B_0`, `B_1` (added to linear layer outputs).
- **Weight Matrices**: `W_O^B`, `W_1^B` (for bias adjustments).
- **Dense Layers**: `C_0`, `C_1`, `D_0`, `D_1`, `E_0`, `E_1` (intermediate transformations).
- **AllReduce**: Distributed communication operations between layers (e.g., `C_0 → C_1`).
- **Color Coding**:
- **Green**: Cache (`K^V`).
- **Pink**: Key matrices (`K_O`, `K_1`).
- **Gray**: Query matrices (`Q_O`, `Q_1`).
- **Blue**: Bias terms (`B_0`, `B_1`).
- **White/Black**: Linear layer weights and outputs.
### Detailed Analysis
1. **Input Flow**:
- Input tokens `A` are processed through linear layers with weights `W_O^K`, `W_O^V`, `W_O^Q` to generate queries, keys, and values.
- Additional tokens (`more tokens`) are appended to the input.
2. **Attention Mechanism**:
- Queries (`Q_O`, `Q_1`) and keys (`K_O`, `K_1`) are computed via linear transformations.
- Attention scores are derived from `Q` and `K`, cached (`K^V`), and passed through softmax.
- Values (`V_O`, `V_1`) are combined with attention scores to produce context-aware outputs.
3. **MLP Processing**:
- Outputs from attention are fed into MLP layers with weights `W_O^B`, `W_1^B` and biases `B_0`, `B_1`.
- Intermediate layers (`C_0`, `C_1`, `D_0`, `D_1`, `E_0`, `E_1`) apply dense transformations.
- **AllReduce** operations synchronize gradients across distributed devices (e.g., `C_0 → C_1`).
4. **Layer Structure**:
- **Top Path**: Represents the first attention and MLP layer (`O`).
- **Bottom Path**: Represents the second attention and MLP layer (`1`).
- Arrows indicate data flow and gradient synchronization.
### Key Observations
- **Distributed Training**: AllReduce operations suggest the model is designed for multi-device training.
- **Hierarchical Processing**: Attention layers capture global context, while MLP layers refine features locally.
- **Efficiency**: Caching (`K^V`) reduces redundant computations in attention mechanisms.
### Interpretation
This architecture resembles a **transformer-based model** optimized for distributed training. The combination of attention and MLP layers enables the network to:
- Capture long-range dependencies via attention.
- Process sequential data through perceptron layers.
- Scale efficiently across devices using AllReduce.
The diagram emphasizes modularity, with clear separation between attention and MLP components. The use of cached keys/values and distributed operations highlights a focus on computational efficiency and scalability, typical in large language models or vision transformers.