# Technical Document Extraction: Self-Instruction Creation and Training Flowchart
## Diagram Overview
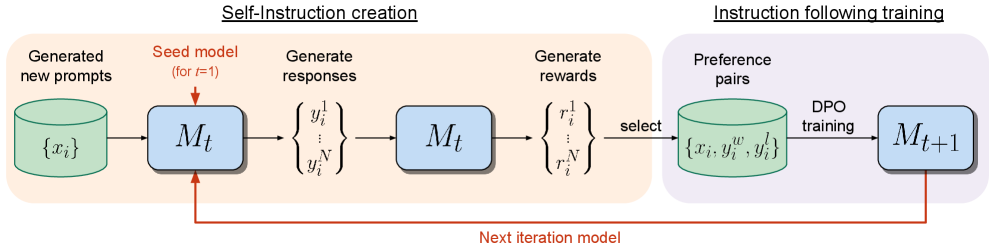
The image depicts a two-phase iterative process for model refinement, combining **self-instruction creation** and **instruction-following training**. The flowchart uses color-coded components to represent data flows and model interactions.
---
## Left Section: Self-Instruction Creation
### Components and Flow
1. **Generated New Prompts**
- Represented by a green cylinder labeled `{x_i}` (input dataset).
- Feeds into the **Seed Model** (`M_t` for `t=1`), a blue box.
2. **Generate Responses**
- The seed model produces responses `{y_i^1, ..., y_i^N}` (outputs for each prompt).
- These responses are fed back into the same model (`M_t`) for iterative refinement.
3. **Generate Rewards**
- The model generates rewards `{r_i^1, ..., r_i^N}` for each response.
- Rewards are used to select **preference pairs** (see right section).
### Key Labels
- Input: `{x_i}` (green cylinder)
- Model: `M_t` (blue box, initial iteration `t=1`)
- Outputs: `{y_i^1, ..., y_i^N}` (responses)
- Rewards: `{r_i^1, ..., r_i^N}` (scalar values)
---
## Right Section: Instruction Following Training
### Components and Flow
1. **Preference Pairs**
- Selected from responses and rewards, stored in a green cylinder labeled `{x_i, y_i^w, y_i^l}`.
- `y_i^w` = preferred response, `y_i^l` = less preferred response.
2. **DPO Training**
- Preference pairs are used for **DPO (Direct Preference Optimization) training**.
- Outputs an updated model `M_{t+1}` (blue box), representing the next iteration.
### Key Labels
- Preference Pairs: `{x_i, y_i^w, y_i^l}` (green cylinder)
- Updated Model: `M_{t+1}` (blue box)
---
## Iterative Process
- A red arrow connects `M_t` (left) to `M_{t+1}` (right), indicating the model is iteratively refined using self-generated data.
- The process loops back to the **next iteration model** (`M_{t+1}`), forming a closed feedback loop.
---
## Color Legend
- **Green**: Data containers (`{x_i}`, `{x_i, y_i^w, y_i^l}`)
- **Blue**: Models (`M_t`, `M_{t+1}`)
- **Red**: Iteration flow (`M_t → M_{t+1}`)
---
## Summary
The flowchart illustrates a **self-supervised training pipeline** where:
1. A seed model generates responses to its own prompts.
2. Rewards are computed for responses, and preference pairs are selected.
3. DPO training on preference pairs updates the model for the next iteration.
4. The updated model repeats the process, creating a cycle of self-improvement.
This structure emphasizes **automated prompt generation**, **reward modeling**, and **preference-based refinement** without human intervention.