## Diagram: Self-Instruction Training Loop
### Overview
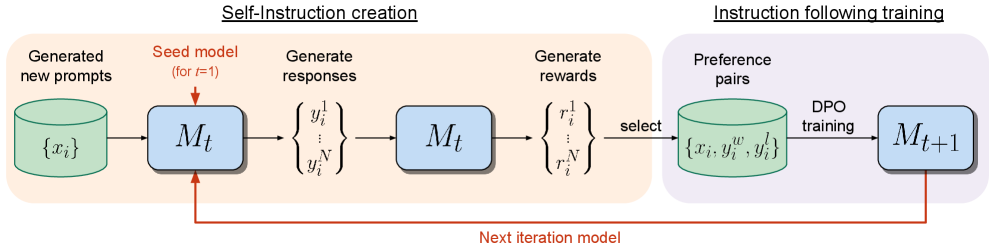
The image illustrates a self-instruction training loop, divided into two main phases: "Self-Instruction creation" and "Instruction following training". The diagram shows the flow of data and processes involved in generating new prompts, responses, rewards, and preference pairs to train a model iteratively.
### Components/Axes
* **Header:** Contains the titles "Self-Instruction creation" and "Instruction following training".
* **Nodes:**
* Green Cylinder: Represents data storage or a collection of data.
* Blue Rounded Rectangle: Represents a model (M) at different stages of training.
* **Arrows:** Indicate the flow of data and processes.
* **Text Labels:** Describe the processes and data at each stage.
### Detailed Analysis
**1. Self-Instruction Creation (Left Side - Orange Background):**
* **Generated new prompts:** A green cylinder labeled "{xi}" represents a collection of generated new prompts.
* **Seed model (for t=1):** The prompts are fed into a blue rounded rectangle labeled "Mt", representing the model at time step t.
* **Generate responses:** The model "Mt" generates responses, represented as "{yi^1 ... yi^N}".
* **Generate rewards:** The responses are then used to generate rewards, represented as "{ri^1 ... ri^N}", using the model "Mt".
**2. Instruction Following Training (Right Side - Purple Background):**
* **Preference pairs:** The rewards are used to select preference pairs, stored in a green cylinder labeled "{xi, yi^w, yi^l}".
* **DPO training:** These preference pairs are used for Direct Preference Optimization (DPO) training to update the model.
* **Mt+1:** The updated model is represented by a blue rounded rectangle labeled "Mt+1".
**3. Feedback Loop:**
* **Next iteration model:** An orange arrow labeled "Next iteration model" connects the output of "Mt+1" back to the input of "Mt" in the "Seed model" stage, indicating the iterative nature of the training loop.
### Key Observations
* The diagram illustrates a closed-loop system where the model generates its own training data.
* The model is updated iteratively using preference pairs derived from generated responses and rewards.
* The "Self-Instruction creation" phase focuses on generating diverse and relevant training data.
* The "Instruction following training" phase focuses on refining the model based on preferences.
### Interpretation
The diagram depicts a self-supervised learning approach where a model learns to improve its instruction-following abilities by generating its own training data and iteratively refining its behavior based on preference learning. The process starts with a seed model and generates prompts, responses, and rewards. These are then used to create preference pairs, which are used to train the model using DPO. The updated model is then used to generate new prompts, continuing the cycle. This approach allows the model to learn from its own mistakes and improve its performance over time. The use of preference learning allows the model to learn from human feedback, which can be used to guide the model towards desired behaviors.