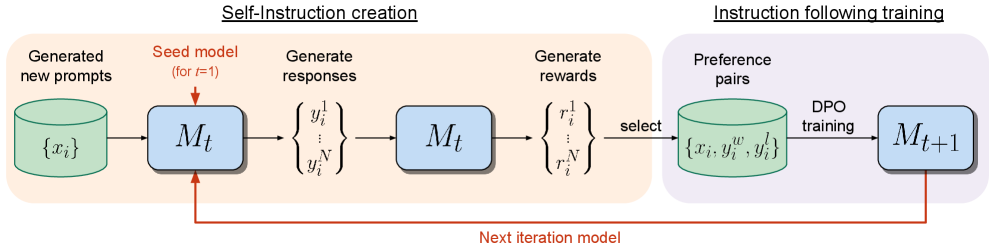
# Technical Diagram Extraction: Iterative Self-Instruction and Training Flow
This image illustrates a technical workflow for an iterative machine learning process, specifically focusing on self-instruction creation and preference-based training (DPO). The process is divided into two primary functional regions.
## 1. High-Level Process Segmentation
* **Region 1 (Left, Orange Background):** **Self-Instruction creation**
* Focuses on generating synthetic data and evaluating it using a current model iteration.
* **Region 2 (Right, Purple Background):** **Instruction following training**
* Focuses on fine-tuning the model using Direct Preference Optimization (DPO) based on the data generated in the first region.
---
## 2. Component Analysis and Data Flow
### Phase 1: Self-Instruction Creation (Orange Region)
1. **Generated new prompts:**
* **Component:** A green cylinder (database icon) labeled $\{x_i\}$.
* **Action:** Serves as the input source for the initial stage.
2. **Model Inference ($M_t$):**
* **Component:** A light blue rounded rectangle labeled $M_t$.
* **Input Annotation:** A red arrow points to the top of the box with the text: "Seed model (for $t=1$)".
* **Action:** The model $M_t$ processes the prompts $\{x_i\}$.
3. **Generate responses:**
* **Component:** A set of mathematical notations in curly braces:
$$\left\{ \begin{matrix} y_i^1 \\ \vdots \\ y_i^N \end{matrix} \right\}$$
* **Action:** The model generates $N$ multiple candidate responses for each prompt.
4. **Model Evaluation ($M_t$):**
* **Component:** A second light blue rounded rectangle labeled $M_t$.
* **Action:** The same model iteration is used to evaluate the generated responses.
5. **Generate rewards:**
* **Component:** A set of mathematical notations in curly braces:
$$\left\{ \begin{matrix} r_i^1 \\ \vdots \\ r_i^N \end{matrix} \right\}$$
* **Action:** Numerical reward scores are assigned to each generated response.
### Phase 2: Instruction Following Training (Purple Region)
1. **Selection Step:**
* **Label:** "select"
* **Action:** An arrow transitions from the rewards to the preference pair database.
2. **Preference pairs:**
* **Component:** A green cylinder (database icon) labeled $\{x_i, y_i^w, y_i^l\}$.
* **Notation Detail:** $y_i^w$ likely represents the "winning" (preferred) response, and $y_i^l$ represents the "losing" response.
3. **DPO training:**
* **Label:** "DPO training"
* **Action:** An arrow indicates the training process applied to the preference data.
4. **Updated Model ($M_{t+1}$):**
* **Component:** A light blue rounded rectangle labeled $M_{t+1}$.
* **Action:** The result of the training is a new, improved version of the model.
---
## 3. Feedback Loop (Iterative Logic)
* **Label:** "Next iteration model"
* **Visual Path:** A solid red line originates from the bottom of the $M_{t+1}$ block, travels horizontally to the left, and points upward into the bottom of the first $M_t$ block.
* **Logic:** This indicates a recursive process where the output of one training cycle ($M_{t+1}$) becomes the input model ($M_t$) for the next cycle of self-instruction and training.
---
## 4. Summary of Textual Labels
| Category | Transcribed Text |
| :--- | :--- |
| **Headers** | Self-Instruction creation, Instruction following training |
| **Process Steps** | Generated new prompts, Generate responses, Generate rewards, select, DPO training |
| **Model States** | $M_t$, $M_{t+1}$ |
| **Data Variables** | $\{x_i\}$, $\{y_i^1 \dots y_i^N\}$, $\{r_i^1 \dots r_i^N\}$, $\{x_i, y_i^w, y_i^l\}$ |
| **Annotations** | Seed model (for $t=1$), Next iteration model |