\n
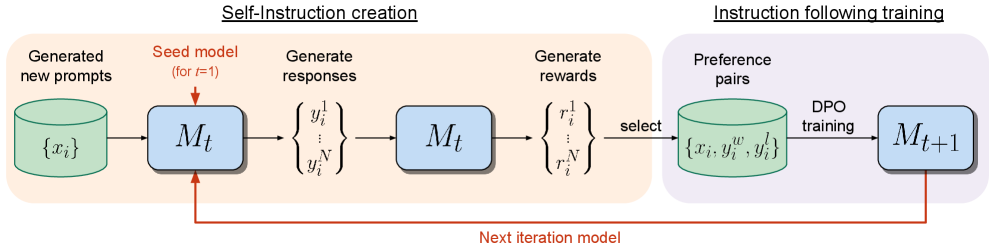
## Diagram: Self-Instruction Creation and Instruction Following Training
### Overview
This diagram illustrates a two-stage process: Self-Instruction creation and Instruction Following training, used to iteratively improve a model (Mt). The process begins with generating new prompts, proceeds through response and reward generation, and culminates in training a new model iteration (Mt+1). A feedback loop connects the final model to the initial prompt generation stage.
### Components/Axes
The diagram is divided into two main sections, visually separated by a light gray background: "Self-Instruction creation" (left) and "Instruction following training" (right). Key components within these sections are represented as labeled boxes and processes.
* **Generated new prompts:** Represented by a cylinder labeled "{xᵢ}".
* **Seed model (for t-1):** Represented by a rectangle labeled "Mₜ".
* **Generate responses:** Represented by a curly brace labeled "{y₁ / y₂ / ... / yN}".
* **Generate rewards:** Represented by a curly brace labeled "{r₁ / r₂ / ... / rN}".
* **Preference pairs:** Represented by a cylinder labeled "{xᵢ, y₁ , y₂}".
* **DPO training:** Text label "DPO training".
* **Next iteration model:** Text label "Next iteration model" with a red arrow connecting the two sections.
* **Next iteration model (Mt+1):** Represented by a rectangle labeled "Mₜ₊₁".
* **Select:** Text label "select".
### Detailed Analysis / Content Details
The diagram depicts a sequential flow of information.
1. **Self-Instruction Creation:**
* New prompts "{xᵢ}" are fed into the seed model "Mₜ".
* The model generates responses "{y₁ / y₂ / ... / yN}".
* These responses are then used to generate rewards "{r₁ / r₂ / ... / rN}".
* A selection process chooses preference pairs "{xᵢ, y₁ , y₂}".
2. **Instruction Following Training:**
* The selected preference pairs are used for DPO (Direct Preference Optimization) training.
* This training results in the next iteration model "Mₜ₊₁".
3. **Feedback Loop:**
* A red arrow labeled "Next iteration model" indicates that the new model "Mₜ₊₁" is used as the seed model for the next iteration of prompt generation, creating a continuous improvement cycle.
### Key Observations
The diagram highlights an iterative process of self-improvement. The use of preference pairs and DPO training suggests a reinforcement learning approach. The feedback loop is crucial for refining the model's ability to follow instructions. The notation of t-1 and t+1 indicates a time-series or iterative process.
### Interpretation
This diagram illustrates a method for improving language models through self-generated training data. The model learns by creating its own prompts, evaluating its responses, and then using this feedback to refine its parameters. This approach is particularly valuable when labeled training data is scarce or expensive to obtain. The DPO training step suggests a focus on aligning the model's behavior with human preferences. The iterative nature of the process allows the model to continuously improve its performance over time. The diagram doesn't provide specific data or numerical values, but rather a conceptual overview of the training pipeline. It suggests a system designed for autonomous learning and refinement of instruction-following capabilities in a language model.