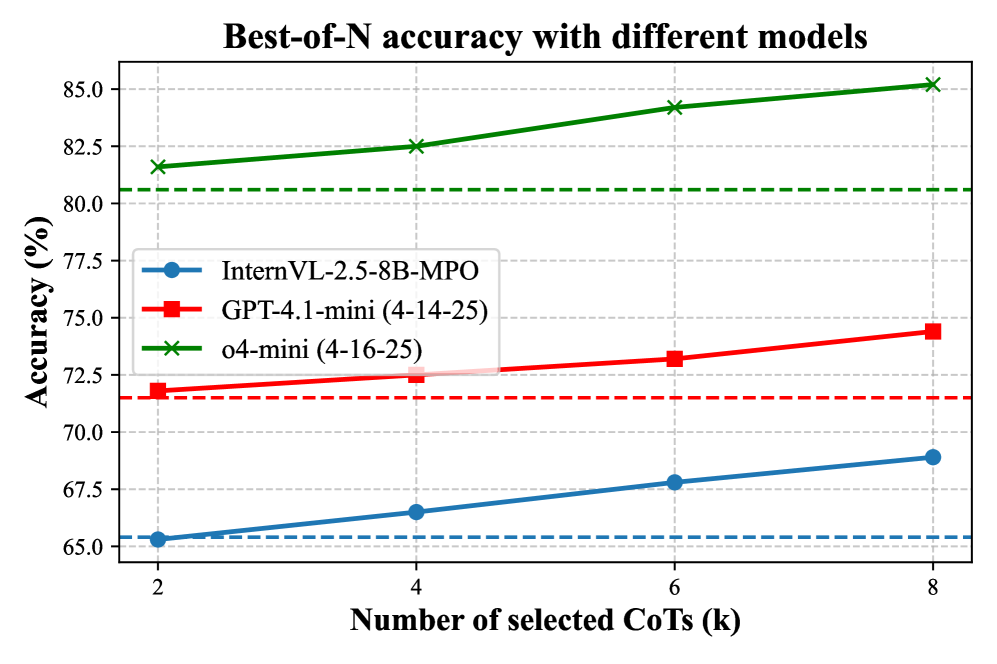
## Line Chart: Best-of-N accuracy with different models
### Overview
The chart compares the accuracy of three AI models (InternVL-2.5-8B-MPO, GPT-4.1-mini, and o4-mini) across different numbers of selected Chain-of-Thought (CoT) steps (k=2,4,6,8). Accuracy is measured in percentage, with distinct performance trends observed for each model.
### Components/Axes
- **X-axis**: Number of selected CoTs (k) - Discrete values at 2, 4, 6, 8
- **Y-axis**: Accuracy (%) - Continuous scale from 65% to 85%
- **Legend**: Located in bottom-left quadrant
- Blue circles: InternVL-2.5-8B-MPO
- Red squares: GPT-4.1-mini (4-14-25)
- Green crosses: o4-mini (4-16-25)
- **Dashed reference line**: Green dashed line at 80.5% accuracy
### Detailed Analysis
1. **InternVL-2.5-8B-MPO** (Blue line):
- Accuracy increases from 65.2% (k=2) to 68.5% (k=8)
- Linear upward trend with consistent slope
- Data points: (2,65.2), (4,66.8), (6,67.6), (8,68.5)
2. **GPT-4.1-mini** (Red line):
- Accuracy rises from 72.1% (k=2) to 74.5% (k=8)
- Steeper slope than InternVL, with sharper increases at k=4 and k=6
- Data points: (2,72.1), (4,73.2), (6,73.8), (8,74.5)
3. **o4-mini** (Green line):
- Highest performance across all k values
- Accuracy starts at 81.5% (k=2) and reaches 85.2% (k=8)
- Slightly concave upward curve with diminishing returns
- Data points: (2,81.5), (4,82.3), (6,84.1), (8,85.2)
### Key Observations
- All models show improved accuracy with more CoT steps
- o4-mini maintains >10% accuracy advantage over GPT-4.1-mini
- Green dashed line at 80.5% intersects o4-mini's performance at k=2
- InternVL-2.5-8B-MPO shows the most gradual improvement curve
- GPT-4.1-mini demonstrates strongest performance gains between k=2→4 and k=4→6
### Interpretation
The data suggests that increasing CoT steps improves model performance across all architectures, with o4-mini demonstrating superior base capabilities and scalability. The green dashed line at 80.5% appears to represent a performance threshold, which o4-mini exceeds even at minimal CoT steps (k=2). The InternVL model shows the most linear improvement pattern, suggesting more predictable scaling with CoT expansion. The GPT-4.1-mini's sharper mid-range gains indicate potential optimization opportunities in its CoT implementation. These results highlight the importance of CoT step selection in model performance optimization, with o4-mini emerging as the most efficient architecture for this task.