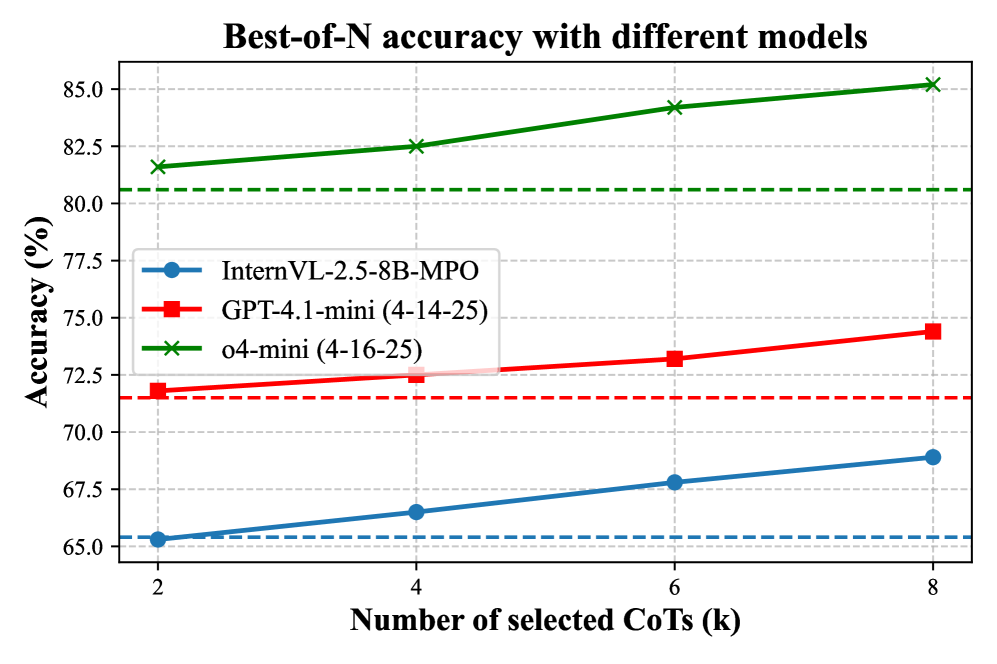
## Line Chart: Best-of-N Accuracy with Different Models
### Overview
This line chart displays the Best-of-N accuracy of three different models – InternVL-2.5-8B-MPO, GPT-4.1-mini (4-14-25), and o4-mini (4-16-25) – as a function of the number of selected CoTs (Contexts or Chains of Thought). The x-axis represents the number of selected CoTs in thousands (k), ranging from 2 to 8. The y-axis represents the accuracy in percentage, ranging from 65% to 85%.
### Components/Axes
* **Title:** Best-of-N accuracy with different models
* **X-axis Label:** Number of selected CoTs (k)
* **Y-axis Label:** Accuracy (%)
* **Legend:**
* InternVL-2.5-8B-MPO (Blue, dashed line with circle markers)
* GPT-4.1-mini (4-14-25) (Red, dashed line with square markers)
* o4-mini (4-16-25) (Green, dashed line with cross markers)
* **X-axis Markers:** 2, 4, 6, 8
* **Y-axis Markers:** 65, 70, 75, 80, 85
### Detailed Analysis
* **InternVL-2.5-8B-MPO (Blue):** The line slopes upward, indicating increasing accuracy with more selected CoTs.
* At 2k CoTs: Approximately 65.5% accuracy.
* At 4k CoTs: Approximately 66.5% accuracy.
* At 6k CoTs: Approximately 68.5% accuracy.
* At 8k CoTs: Approximately 69.5% accuracy.
* **GPT-4.1-mini (4-14-25) (Red):** The line initially remains relatively flat, then decreases slightly before increasing again.
* At 2k CoTs: Approximately 72.5% accuracy.
* At 4k CoTs: Approximately 72.5% accuracy.
* At 6k CoTs: Approximately 71.5% accuracy.
* At 8k CoTs: Approximately 72.5% accuracy.
* **o4-mini (4-16-25) (Green):** The line slopes consistently upward, showing a clear positive correlation between the number of selected CoTs and accuracy.
* At 2k CoTs: Approximately 81.5% accuracy.
* At 4k CoTs: Approximately 82.5% accuracy.
* At 6k CoTs: Approximately 84.0% accuracy.
* At 8k CoTs: Approximately 85.0% accuracy.
### Key Observations
* The o4-mini model consistently exhibits the highest accuracy across all tested numbers of CoTs.
* The InternVL-2.5-8B-MPO model shows the lowest accuracy, but its performance improves steadily with more CoTs.
* GPT-4.1-mini's accuracy remains relatively stable, with a slight dip at 6k CoTs.
* The accuracy gains diminish as the number of CoTs increases, particularly for the o4-mini model.
### Interpretation
The chart demonstrates the impact of increasing the number of selected Contexts (CoTs) on the Best-of-N accuracy of different language models. The o4-mini model appears to be the most effective in leveraging additional CoTs to improve its performance. The InternVL-2.5-8B-MPO model benefits the most from increasing the number of CoTs, suggesting it is more sensitive to the quality and diversity of the contexts provided. The relatively stable performance of GPT-4.1-mini suggests it may have already reached a performance plateau or is less reliant on the number of CoTs. The diminishing returns observed with increasing CoTs indicate that there is a point beyond which adding more contexts does not significantly improve accuracy. This could be due to redundancy in the contexts or limitations in the model's ability to effectively process and integrate a large number of inputs. The chart highlights the trade-off between computational cost (increasing the number of CoTs) and accuracy gains.