TECHNICAL ASSET FINGERPRINT
7702f67d983ba876a70235b3
Click to view fullscreen
Press ESC or click to close
FOUND IN PAPERS
EXPERT: healer-alpha-free VERSION 1
RUNTIME: free/openrouter/healer-alpha
INTEL_VERIFIED
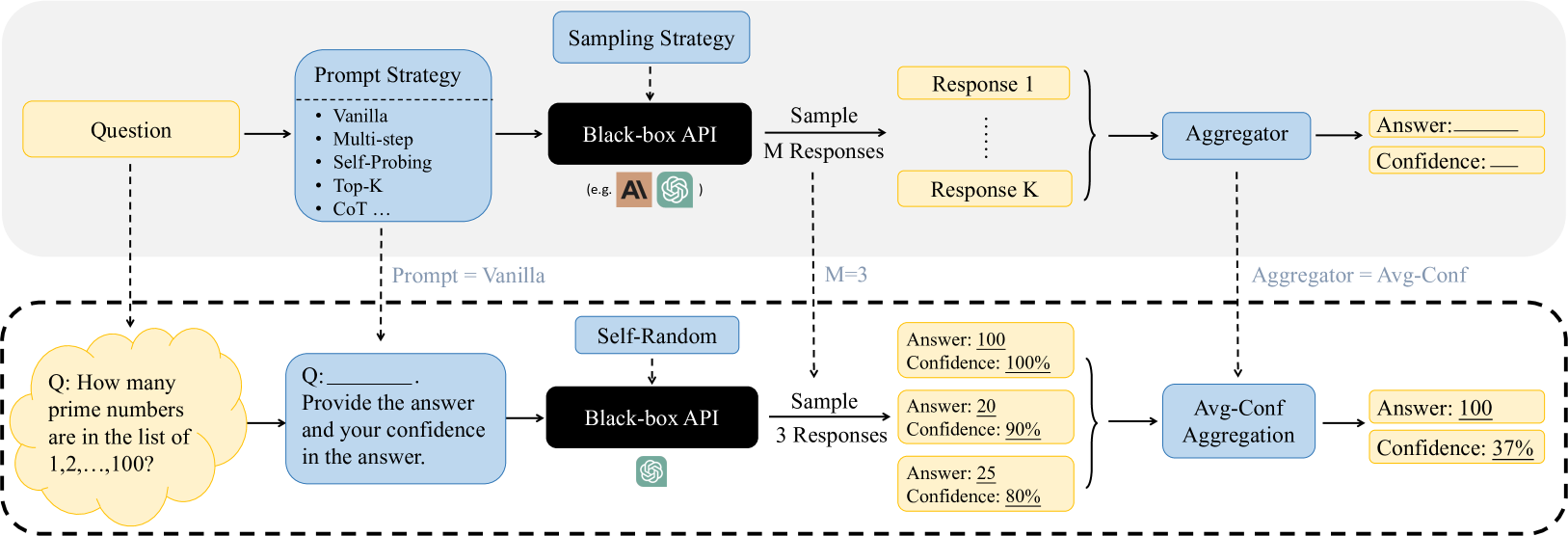
## Diagram: Black-Box API Query Process with Prompt Strategies and Confidence Aggregation
### Overview
The image is a technical flowchart diagram illustrating a two-stage process for querying a black-box AI API. The top section outlines a general framework for using various prompt strategies and sampling methods to generate multiple responses, which are then aggregated to produce a final answer with a confidence score. The bottom section, enclosed in a dashed border, provides a concrete instantiation of this framework using a specific example question, a "Vanilla" prompt strategy, a "Self-Random" sampling strategy with M=3, and an "Avg-Conf" (Average Confidence) aggregation method.
### Components/Axes
The diagram is structured into two horizontal sections.
**Top Section (General Framework):**
1. **Input:** A yellow box labeled "Question" on the far left.
2. **Prompt Strategy Module:** A light blue box labeled "Prompt Strategy" containing a bulleted list:
* Vanilla
* Multi-step
* Self-Probing
* Top-K
* CoT ...
3. **Sampling Strategy Module:** A light blue box labeled "Sampling Strategy" above the API.
4. **Core Processing Unit:** A black box labeled "Black-box API" with small logos for "AI" and "OpenAI" (represented by a green swirl icon) beneath the text "(e.g., )".
5. **Sampling Output:** An arrow labeled "Sample M Responses" leads to a set of yellow boxes labeled "Response 1" through "Response K", indicating multiple outputs.
6. **Aggregation Module:** A light blue box labeled "Aggregator".
7. **Final Output:** Two yellow boxes on the far right: "Answer: ______" and "Confidence: ______".
**Bottom Section (Specific Example - within dashed border):**
1. **Example Question:** A yellow cloud-shaped box containing the text: "Q: How many prime numbers are in the list of 1,2,...,100?".
2. **Example Prompt:** A light blue box connected by a dashed line labeled "Prompt = Vanilla". It contains: "Q: ______. Provide the answer and your confidence in the answer."
3. **Example Sampling Strategy:** A light blue box labeled "Self-Random" above the API.
4. **Example API:** A black box labeled "Black-box API" with the green OpenAI logo.
5. **Example Sampling Output:** An arrow labeled "Sample 3 Responses" (with "M=3" noted above the dashed line) leads to three yellow boxes:
* "Answer: 100", "Confidence: 100%"
* "Answer: 20", "Confidence: 90%"
* "Answer: 25", "Confidence: 80%"
6. **Example Aggregation:** A light blue box labeled "Avg-Conf Aggregation", connected by a dashed line labeled "Aggregator = Avg-Conf".
7. **Example Final Output:** Two yellow boxes: "Answer: 100" and "Confidence: 37%".
### Detailed Analysis
The diagram explicitly maps the flow of information and control parameters from the general framework to the specific example.
* **Prompt Strategy Flow:** The "Question" feeds into the "Prompt Strategy" module. In the example, the chosen strategy is "Vanilla", which formats the raw question into a prompt requesting both an answer and a confidence score.
* **API Interaction:** The formatted prompt is sent to the "Black-box API". The "Sampling Strategy" (e.g., "Self-Random") dictates how the API is queried to produce diversity in outputs.
* **Response Generation:** The API is sampled `M` times (M=3 in the example) to generate `K` responses (K=3 shown). Each response is a paired data point: an answer and a self-reported confidence percentage.
* **Aggregation Logic:** The multiple response pairs are fed into the "Aggregator". The example uses "Avg-Conf Aggregation". The final confidence (37%) is the arithmetic mean of the individual confidences (100%, 90%, 80% = 270% / 3 = 90%? **Note: There is a discrepancy here.** The diagram states the final confidence is 37%, but the average of 100, 90, and 80 is 90. This suggests the "Avg-Conf" method may not be a simple mean, or the numbers in the example are illustrative and not mathematically consistent. The final answer "100" appears to be selected from the response with the highest individual confidence (100%).
* **Spatial Grounding:** The "Sampling Strategy" box is positioned above the "Black-box API". The "Aggregator" box is positioned to the right of the response set. The example section is clearly demarcated by a dashed border below the general framework.
### Key Observations
1. **Modular Design:** The framework is highly modular, allowing independent selection of prompt strategy, sampling strategy, and aggregation method.
2. **Black-Box Abstraction:** The API is treated as an opaque component; only its inputs (prompts) and outputs (text responses) are considered.
3. **Confidence as a Key Output:** The process explicitly seeks to quantify uncertainty by collecting and aggregating confidence scores alongside answers.
4. **Example Discrepancy:** The numerical example contains an internal inconsistency. The stated final confidence of 37% does not match the simple average of the provided confidence scores (90%). This implies either a more complex aggregation function is used (e.g., weighted by answer consistency) or the example values are placeholders not meant to be arithmetically precise.
5. **Answer Selection:** In the example, the final answer "100" corresponds to the response with the highest individual confidence (100%), not necessarily the most frequent answer (which would be ambiguous here with three different answers: 100, 20, 25).
### Interpretation
This diagram illustrates a methodology for improving the reliability and calibrating the uncertainty of outputs from large language models (LLMs) accessed via black-box APIs. The core idea is to move beyond single-query interactions.
* **Peircean Investigation:** The process embodies a pragmatic, investigative approach. Instead of accepting a single answer from the API (a "Firstness" of raw output), it generates multiple hypotheses (responses) through varied prompting and sampling ("Secondness" of interaction and reaction). The aggregation step ("Thirdness") establishes a rule or law—the final answer and its confidence—based on the pattern observed across the multiple interactions.
* **Managing Stochasticity:** LLMs are stochastic; the same prompt can yield different results. This framework embraces that stochasticity by sampling multiple times and using aggregation to find a consensus or most reliable output.
* **Quantifying Uncertainty:** By prompting the model to self-report confidence and then aggregating those scores, the system attempts to produce a meta-cognitive estimate of its own reliability. The low final confidence (37%) in the example, despite high individual confidences, signals significant disagreement among the model's own responses, warning the user that the answer "100" may not be trustworthy.
* **Practical Implication:** This pattern is valuable for high-stakes applications where understanding the certainty of an AI's answer is as important as the answer itself. It provides a systematic way to query AI systems more rigorously. The discrepancy in the example's math, however, highlights that the exact aggregation logic is a critical, implementation-specific detail not fully explained by the diagram alone.
DECODING INTELLIGENCE...