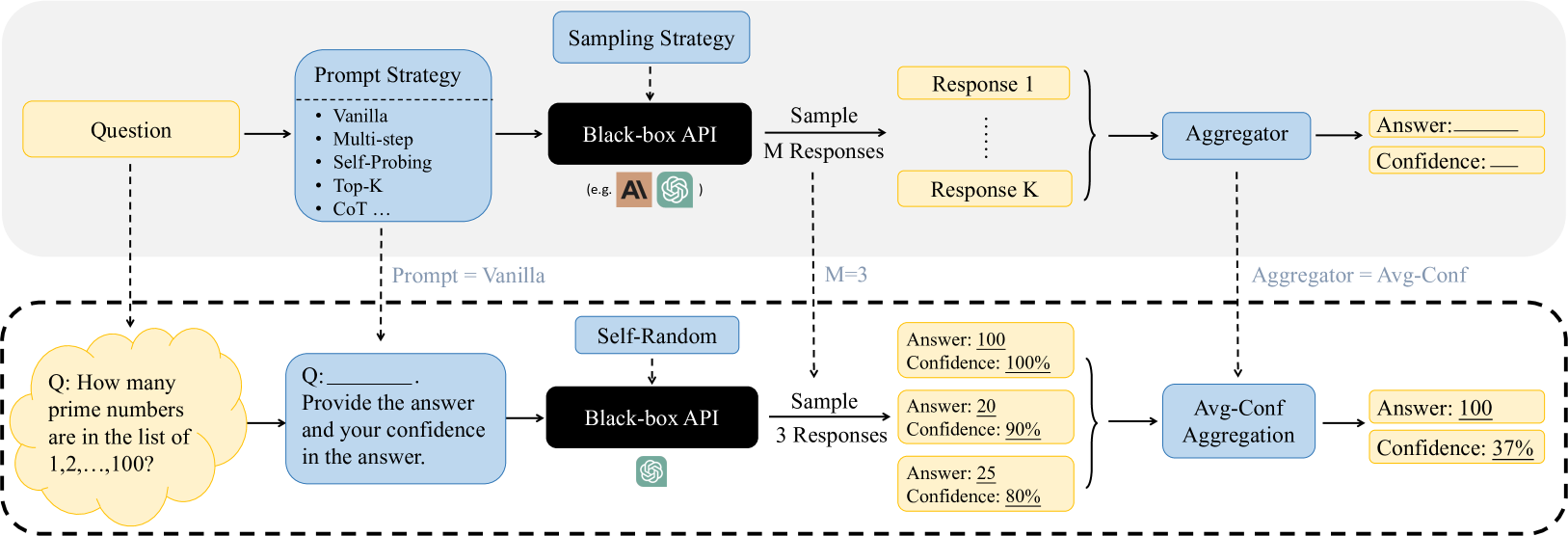
## Process Diagram: Multi-Strategy Question Answering with Confidence Aggregation
### Overview
The diagram illustrates a two-stage process for answering questions using language models. The top section shows a general framework for generating and aggregating responses, while the bottom section demonstrates a specific example with numerical confidence calculations.
### Components/Axes
1. **Top Section (General Framework)**
- **Input**: Question (e.g., "How many prime numbers are in the list of 1,2,...,100?")
- **Prompt Strategies**:
- Vanilla
- Multi-step
- Self-Probing
- Top-K
- CoT (Chain-of-Thought)
- **Sampling Strategy**: Black-box API with M=3 responses
- **Output**: Aggregated Answer + Confidence (using Avg-Conf Aggregation)
2. **Bottom Section (Specific Example)**
- **Question**: "How many prime numbers are in the list of 1,2,...,100?"
- **Prompt Strategy**: Self-Random
- **Sampling**: 3 responses from Black-box API
- **Responses**:
- Response 1: Answer=100, Confidence=100%
- Response 2: Answer=20, Confidence=90%
- Response 3: Answer=25, Confidence=80%
- **Aggregation**:
- Final Answer=100
- Final Confidence=37%
### Detailed Analysis
- **Prompt Strategies**: The top section lists five distinct prompting approaches, with "Vanilla" being the baseline method.
- **Sampling**: All responses are generated through a black-box API, with M=3 responses sampled in both sections.
- **Confidence Values**:
- Individual responses show high confidence (80-100%)
- Aggregated confidence in the example is significantly lower (37%)
- **Aggregation Method**: Uses "Avg-Conf" (average confidence) calculation, though the example shows non-linear behavior.
### Key Observations
1. **Confidence Discrepancy**: Despite two responses showing high confidence (100% and 90%), the aggregated confidence drops to 37%.
2. **Response Variance**: Answers range from 20 to 100, indicating potential model uncertainty about prime number counts.
3. **Strategy Impact**: The example uses "Self-Random" prompting, suggesting different strategies may yield different confidence patterns.
### Interpretation
The diagram demonstrates how combining multiple model responses can surface uncertainty that individual responses might mask. The 37% aggregated confidence in the example suggests:
1. **Model Uncertainty**: Even with high-confidence individual answers, the system recognizes significant disagreement between responses.
2. **Aggregation Method**: The "Avg-Conf" method appears to weight responses differently than simple averaging, possibly incorporating variance or other statistical measures.
3. **Practical Implications**: This framework helps quantify uncertainty in AI responses, crucial for applications requiring reliability assessment.
The process highlights the importance of response diversity and confidence calibration in language model applications, particularly for factual questions with definitive answers.