## Bar Chart: Feature Comparison of Language Models
### Overview
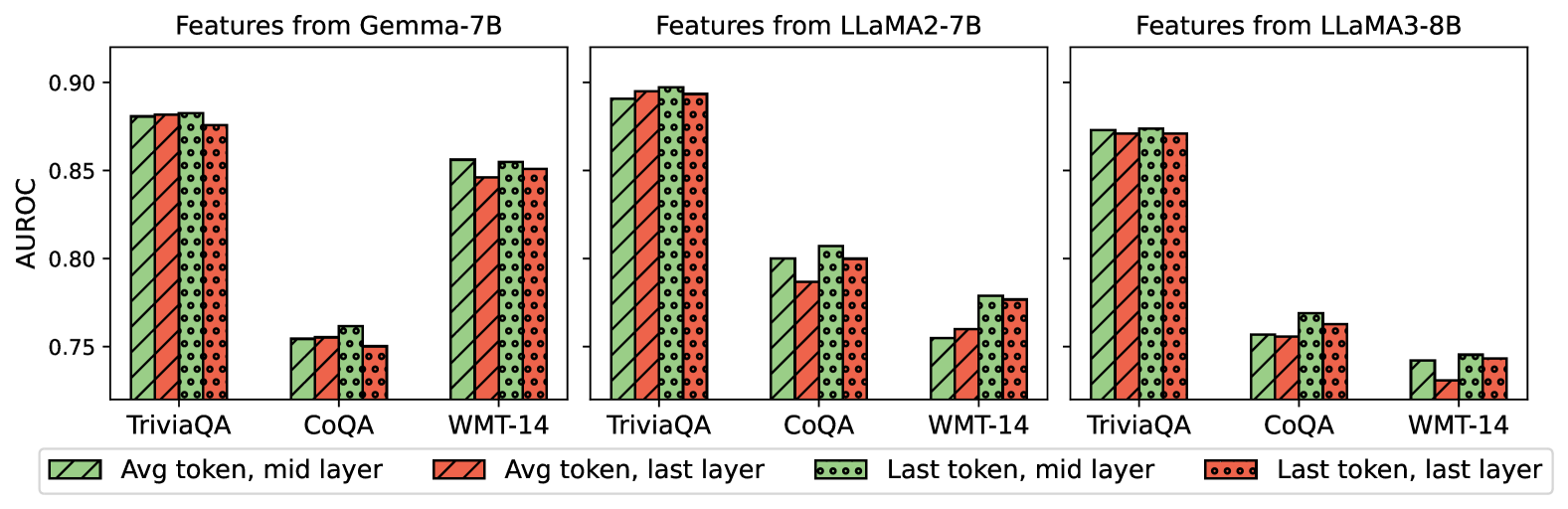
The image presents a series of bar charts comparing the AUROC (Area Under the Receiver Operating Characteristic curve) scores of different feature extraction methods from three language models: Gemma-7B, LLaMA2-7B, and LLaMA3-8B. The charts compare the performance on three tasks: TriviaQA, CoQA, and WMT-14. The feature extraction methods are "Avg token, mid layer", "Avg token, last layer", "Last token, mid layer", and "Last token, last layer".
### Components/Axes
* **Title:** The image is composed of three separate bar charts, each titled:
* "Features from Gemma-7B" (top-left)
* "Features from LLaMA2-7B" (top-center)
* "Features from LLaMA3-8B" (top-right)
* **Y-axis:** Labeled "AUROC" with a scale from approximately 0.74 to 0.91.
* **X-axis:** Categorical, representing the tasks: TriviaQA, CoQA, and WMT-14.
* **Legend:** Located at the bottom of the image, associating colors and patterns with feature extraction methods:
* Green with diagonal lines: "Avg token, mid layer"
* Red with diagonal lines: "Avg token, last layer"
* Green with circles: "Last token, mid layer"
* Red with circles: "Last token, last layer"
### Detailed Analysis
#### Features from Gemma-7B
* **TriviaQA:**
* Avg token, mid layer (green, diagonal lines): ~0.87
* Avg token, last layer (red, diagonal lines): ~0.86
* Last token, mid layer (green, circles): ~0.87
* Last token, last layer (red, circles): ~0.86
* **CoQA:**
* Avg token, mid layer (green, diagonal lines): ~0.76
* Avg token, last layer (red, diagonal lines): ~0.75
* Last token, mid layer (green, circles): ~0.76
* Last token, last layer (red, circles): ~0.75
* **WMT-14:**
* Avg token, mid layer (green, diagonal lines): ~0.86
* Avg token, last layer (red, diagonal lines): ~0.85
* Last token, mid layer (green, circles): ~0.86
* Last token, last layer (red, circles): ~0.85
#### Features from LLaMA2-7B
* **TriviaQA:**
* Avg token, mid layer (green, diagonal lines): ~0.89
* Avg token, last layer (red, diagonal lines): ~0.89
* Last token, mid layer (green, circles): ~0.90
* Last token, last layer (red, circles): ~0.89
* **CoQA:**
* Avg token, mid layer (green, diagonal lines): ~0.80
* Avg token, last layer (red, diagonal lines): ~0.80
* Last token, mid layer (green, circles): ~0.80
* Last token, last layer (red, circles): ~0.80
* **WMT-14:**
* Avg token, mid layer (green, diagonal lines): ~0.76
* Avg token, last layer (red, diagonal lines): ~0.76
* Last token, mid layer (green, circles): ~0.78
* Last token, last layer (red, circles): ~0.78
#### Features from LLaMA3-8B
* **TriviaQA:**
* Avg token, mid layer (green, diagonal lines): ~0.85
* Avg token, last layer (red, diagonal lines): ~0.85
* Last token, mid layer (green, circles): ~0.85
* Last token, last layer (red, circles): ~0.85
* **CoQA:**
* Avg token, mid layer (green, diagonal lines): ~0.76
* Avg token, last layer (red, diagonal lines): ~0.76
* Last token, mid layer (green, circles): ~0.76
* Last token, last layer (red, circles): ~0.76
* **WMT-14:**
* Avg token, mid layer (green, diagonal lines): ~0.73
* Avg token, last layer (red, diagonal lines): ~0.73
* Last token, mid layer (green, circles): ~0.74
* Last token, last layer (red, circles): ~0.74
### Key Observations
* For all three models, performance on TriviaQA is generally higher than on CoQA and WMT-14.
* The choice of layer (mid vs. last) and token aggregation (avg vs. last) has a relatively small impact on AUROC scores within each task and model.
* LLaMA2-7B generally shows the highest AUROC scores, especially on TriviaQA.
* LLaMA3-8B shows the lowest AUROC scores on WMT-14.
### Interpretation
The bar charts provide a comparative analysis of feature extraction methods from different language models based on their AUROC scores on various tasks. The data suggests that the LLaMA2-7B model performs slightly better overall compared to Gemma-7B and LLaMA3-8B. The performance differences between using the average token versus the last token, and the mid-layer versus the last layer, are relatively minor, indicating that the choice of feature extraction method is not as critical as the choice of the language model itself. The lower scores on CoQA and WMT-14 across all models suggest that these tasks are more challenging for the models compared to TriviaQA.