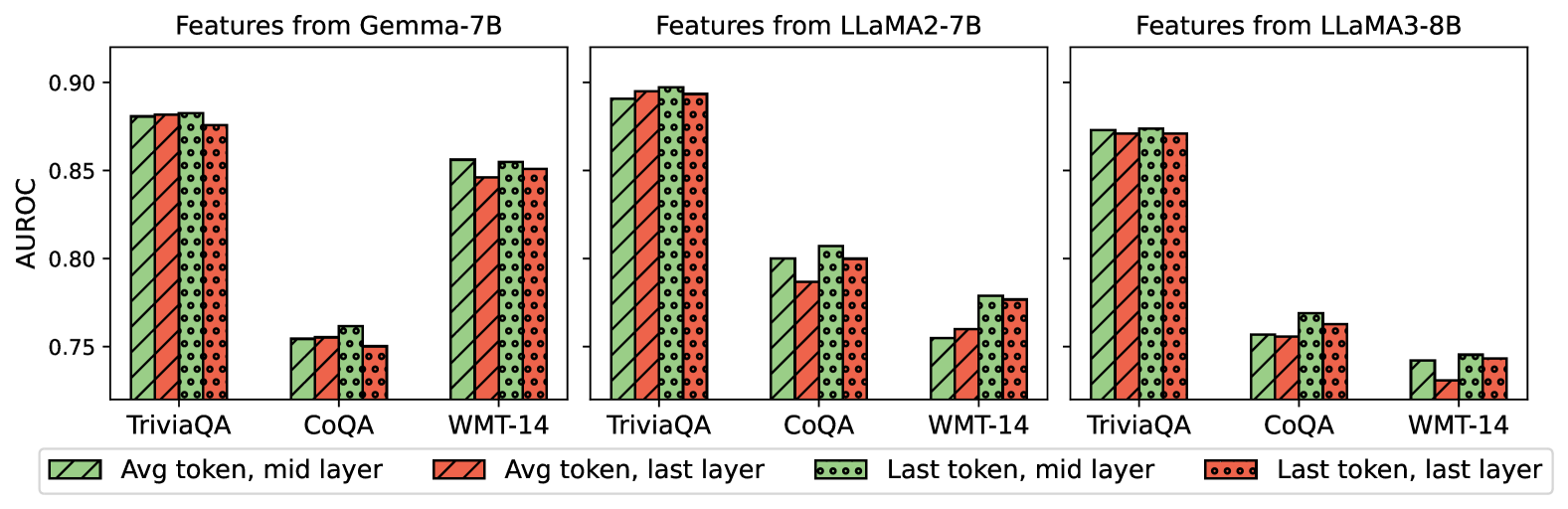
## Bar Chart: AUROC Comparison Across Models and Features
### Overview
The image presents a grouped bar chart comparing the Area Under the Receiver Operating Characteristic curve (AUROC) values for three language models (Gemma-7B, LLaMA2-7B, LLaMA3-8B) across three datasets (TriviaQA, CoQA, WMT-14). Four feature types are evaluated:
1. **Avg token, mid layer** (solid green)
2. **Avg token, last layer** (solid red)
3. **Last token, mid layer** (dotted green)
4. **Last token, last layer** (dotted red)
### Components/Axes
- **X-axis**: Datasets (TriviaQA, CoQA, WMT-14)
- **Y-axis**: AUROC values (0.75–0.90, increments of 0.05)
- **Legend**: Located at the bottom, mapping colors/patterns to feature types.
- **Model Sections**: Three vertical groupings (left to right) for each model.
### Detailed Analysis
#### Gemma-7B
- **TriviaQA**:
- Avg token, mid layer: ~0.88
- Avg token, last layer: ~0.87
- Last token, mid layer: ~0.89
- Last token, last layer: ~0.88
- **CoQA**:
- Avg token, mid layer: ~0.76
- Avg token, last layer: ~0.75
- Last token, mid layer: ~0.77
- Last token, last layer: ~0.75
- **WMT-14**:
- Avg token, mid layer: ~0.86
- Avg token, last layer: ~0.85
- Last token, mid layer: ~0.87
- Last token, last layer: ~0.86
#### LLaMA2-7B
- **TriviaQA**:
- Avg token, mid layer: ~0.89
- Avg token, last layer: ~0.89
- Last token, mid layer: ~0.90
- Last token, last layer: ~0.89
- **CoQA**:
- Avg token, mid layer: ~0.80
- Avg token, last layer: ~0.79
- Last token, mid layer: ~0.81
- Last token, last layer: ~0.80
- **WMT-14**:
- Avg token, mid layer: ~0.76
- Avg token, last layer: ~0.75
- Last token, mid layer: ~0.77
- Last token, last layer: ~0.76
#### LLaMA3-8B
- **TriviaQA**:
- Avg token, mid layer: ~0.87
- Avg token, last layer: ~0.87
- Last token, mid layer: ~0.88
- Last token, last layer: ~0.87
- **CoQA**:
- Avg token, mid layer: ~0.76
- Avg token, last layer: ~0.75
- Last token, mid layer: ~0.77
- Last token, last layer: ~0.75
- **WMT-14**:
- Avg token, mid layer: ~0.74
- Avg token, last layer: ~0.73
- Last token, mid layer: ~0.75
- Last token, last layer: ~0.74
### Key Observations
1. **TriviaQA Dominance**: All models achieve highest AUROC on TriviaQA, suggesting it aligns better with their architectures.
2. **Mid Layer Superiority**: Features from the mid layer (both avg and last token) consistently outperform last layer features across models.
3. **LLaMA2-7B Peak**: LLaMA2-7B achieves the highest AUROC (0.90) for Last token, mid layer on TriviaQA.
4. **WMT-14 Struggles**: All models perform worst on WMT-14, with AUROC values dropping below 0.80.
5. **Last Token Variability**: Last token features show mixed performance, sometimes matching or slightly exceeding avg token results.
### Interpretation
The data suggests that **mid-layer features** (both average and last token) are more effective for these tasks than last-layer features, potentially due to mid layers capturing richer contextual information. TriviaQA’s higher performance across models implies it is more compatible with the models’ design, while WMT-14’s lower scores may reflect task complexity or domain mismatch. The consistency of mid-layer superiority across models indicates this is a generalizable trend rather than model-specific behavior.