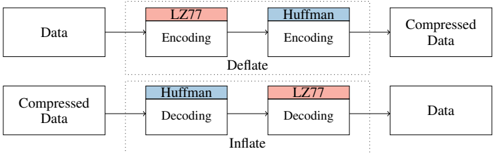
## Diagram: Data Compression/Decompression Workflow
### Overview
The diagram illustrates a bidirectional workflow for compressing and decompressing data using two encoding/decoding methods: **LZ77** (red) and **Huffman** (blue). The process is split into two phases: **Deflate** (compression) and **Inflate** (decompression).
### Components/Axes
- **Deflate Phase (Top Section):**
- **Input:** "Data" (leftmost box).
- **Steps:**
1. **LZ77 Encoding** (red box).
2. **Huffman Encoding** (blue box).
- **Output:** "Compressed Data" (rightmost box).
- **Flow:** Arrows indicate sequential processing from left to right.
- **Inflate Phase (Bottom Section):**
- **Input:** "Compressed Data" (leftmost box).
- **Steps:**
1. **Huffman Decoding** (blue box).
2. **LZ77 Decoding** (red box).
- **Output:** "Data" (rightmost box).
- **Flow:** Arrows indicate sequential processing from left to right.
- **Legend:**
- **Red:** LZ77 (used in both encoding and decoding).
- **Blue:** Huffman (used in both encoding and decoding).
### Detailed Analysis
- **Deflate Workflow:**
- Raw data is first compressed using **LZ77** (lossless dictionary-based compression), then further compressed with **Huffman** (entropy encoding).
- The order of encoding (LZ77 → Huffman) suggests prioritizing redundancy removal before statistical compression.
- **Inflate Workflow:**
- Compressed data is first decompressed via **Huffman** (reversing entropy encoding), then **LZ77** (reconstructing original sequences).
- The reversed order (Huffman → LZ77) ensures proper decompression.
- **Color Consistency:**
- All LZ77 components (encoding/decoding) are red.
- All Huffman components (encoding/decoding) are blue.
### Key Observations
1. **Bidirectional Symmetry:** The workflow mirrors itself in Deflate/Inflate, with encoding/decoding steps reversed.
2. **Layered Compression:** LZ77 and Huffman are applied sequentially, not in parallel, to maximize efficiency.
3. **No Numerical Data:** The diagram lacks quantitative metrics (e.g., compression ratios), focusing instead on process flow.
### Interpretation
This diagram represents the **Deflate algorithm**, a hybrid compression method combining LZ77 and Huffman coding. The separation into Deflate (compression) and Inflate (decompression) phases highlights the algorithm’s design for efficiency and reversibility.
- **Technical Implications:**
- LZ77 handles repetitive patterns (e.g., strings of characters), while Huffman optimizes bit-level redundancy.
- The strict order of operations ensures that decompression (Inflate) can reliably reconstruct the original data.
- **Practical Use:**
- Commonly used in formats like ZIP and gzip.
- The diagram omits details like dictionary management (LZ77) or frequency tables (Huffman), which are critical for implementation.
- **Anomalies:**
- No explicit error-handling mechanisms (e.g., checksums) are shown, which are typically part of real-world compression pipelines.
This workflow emphasizes lossless compression, ensuring data integrity while reducing size through layered algorithms.