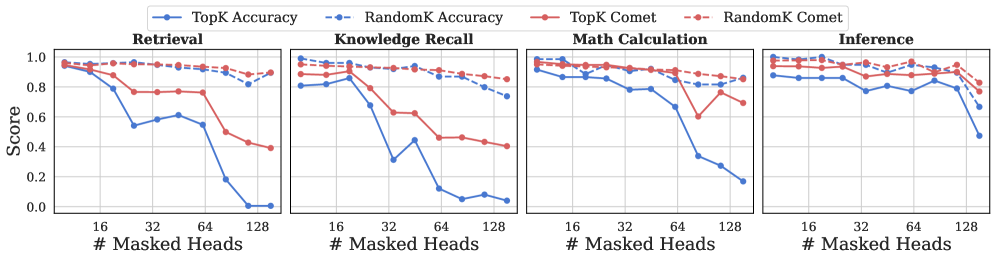
## Line Graphs: Accuracy Metrics vs. Masked Heads
### Overview
The image contains four line graphs comparing accuracy metrics across four tasks (Retrieval, Knowledge Recall, Math Calculation, Inference) as the number of masked heads increases (16, 32, 64, 128). Each graph tracks four metrics: TopK Accuracy (solid blue), RandomK Accuracy (dashed blue), TopK Comet (solid red), and RandomK Comet (dashed red). Scores range from 0 to 1.0.
### Components/Axes
- **X-axis**: "# Masked Heads" (16, 32, 64, 128)
- **Y-axis**: "Score" (0.0 to 1.0)
- **Legends**:
- Top-left: TopK Accuracy (solid blue), RandomK Accuracy (dashed blue), TopK Comet (solid red), RandomK Comet (dashed red)
- **Subplots**:
- Top-left: Retrieval
- Top-right: Knowledge Recall
- Bottom-left: Math Calculation
- Bottom-right: Inference
### Detailed Analysis
#### Retrieval
- **TopK Accuracy**: Starts at ~0.95 (16 masked heads), drops sharply to ~0.8 (32), ~0.6 (64), and ~0.2 (128).
- **RandomK Accuracy**: Remains stable (~0.8) across all masked heads.
- **TopK Comet**: Declines gradually from ~0.95 to ~0.75.
- **RandomK Comet**: Stable (~0.85) with minor fluctuations.
#### Knowledge Recall
- **TopK Accuracy**: Starts at ~0.9, drops to ~0.7 (32), ~0.5 (64), and ~0.3 (128).
- **RandomK Accuracy**: Stable (~0.8) with a slight dip at 64 (~0.75).
- **TopK Comet**: Declines from ~0.9 to ~0.6.
- **RandomK Comet**: Stable (~0.85).
#### Math Calculation
- **TopK Accuracy**: Starts at ~0.95, drops to ~0.8 (32), ~0.6 (64), and ~0.4 (128).
- **RandomK Accuracy**: Stable (~0.85) with a minor dip at 64 (~0.8).
- **TopK Comet**: Declines from ~0.95 to ~0.75.
- **RandomK Comet**: Stable (~0.85).
#### Inference
- **TopK Accuracy**: Starts at ~0.9, drops to ~0.7 (32), ~0.6 (64), and ~0.4 (128).
- **RandomK Accuracy**: Stable (~0.85) with a slight dip at 64 (~0.8).
- **TopK Comet**: Declines from ~0.9 to ~0.75.
- **RandomK Comet**: Stable (~0.85).
### Key Observations
1. **TopK metrics degrade sharply** as masked heads increase, especially in Retrieval and Math Calculation.
2. **RandomK metrics remain stable** across all tasks and masked heads, suggesting robustness.
3. **TopK Comet** consistently outperforms RandomK Comet in Retrieval and Math Calculation but underperforms in Knowledge Recall and Inference.
4. **RandomK Comet** maintains near-constant performance (~0.85) across all tasks.
### Interpretation
The data suggests that **TopK methods are sensitive to masked heads**, with performance collapsing as masking increases. In contrast, **RandomK methods show resilience**, maintaining stable scores regardless of masking. The Comet metrics (TopK/RandomK) appear more robust than Accuracy metrics, particularly in Knowledge Recall and Inference. This implies that Comet-based evaluations might better capture task-specific nuances under varying masking conditions. The sharp decline in TopK Accuracy for Retrieval and Math Calculation at 128 masked heads highlights a critical vulnerability in these methods when extensive masking is applied.