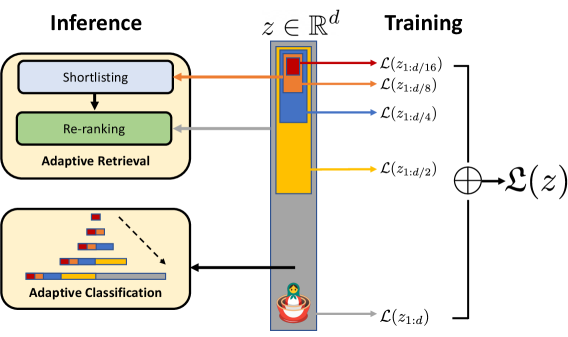
## Diagram: Adaptive Retrieval and Classification System with Hierarchical Training
### Overview
The diagram illustrates a two-phase system: **Inference** (top) and **Training** (right). The Inference phase includes components for shortlisting, re-ranking, adaptive retrieval, and adaptive classification. The Training phase depicts a hierarchical loss structure with decreasing granularity (e.g., `L(z1:d/16)`, `L(z1:d/8)`, etc.) and a final aggregated loss `L(z)`. A circular element with a cross and a stylized figure (red base, yellow top) connects the phases.
---
### Components/Axes
1. **Inference Phase**:
- **Shortlisting**: Initial candidate selection (orange arrow).
- **Re-ranking**: Refines shortlisted candidates (gray arrow).
- **Adaptive Retrieval**: Processes re-ranked candidates (blue arrow).
- **Adaptive Classification**: Outputs hierarchical confidence scores (bar chart with red, blue, yellow segments).
2. **Training Phase**:
- **Hierarchical Loss Stack**: Vertical column with labeled loss functions:
- `L(z1:d/16)` (red)
- `L(z1:d/8)` (orange)
- `L(z1:d/4)` (blue)
- `L(z1:d/2)` (yellow)
- `L(z1:d)` (gray)
- **Aggregated Loss**: Final loss `L(z)` (circle with cross).
- **Agent/Model**: Stylized figure (red base, yellow top) at the bottom, likely representing the model being trained.
---
### Detailed Analysis
- **Inference Flow**:
- Shortlisting → Re-ranking → Adaptive Retrieval → Adaptive Classification.
- Adaptive Classification outputs a bar chart with diminishing segment sizes (red > blue > yellow), suggesting confidence scores or feature weights.
- **Training Hierarchy**:
- Loss functions are labeled with decreasing fractions (`1/16` to `1/d`), implying multi-scale or hierarchical training.
- The circular `L(z)` with a cross may represent a loss aggregation or optimization step (e.g., gradient descent).
- **Connections**:
- A dashed arrow links Adaptive Classification to the Training phase, indicating feedback from classification to training losses.
- The agent/model at the bottom receives input from the aggregated loss `L(z)`.
---
### Key Observations
1. **Hierarchical Training**: The loss functions (`L(z1:d/16)` to `L(z1:d)`) suggest a multi-resolution training strategy, where finer-grained losses (`1/16`, `1/8`) are prioritized early, and coarser losses (`1/d`) dominate later.
2. **Adaptive Feedback Loop**: The dashed arrow implies that Adaptive Classification’s output influences the training process, enabling dynamic adjustment of the model.
3. **Symbolism**: The circular `L(z)` with a cross may symbolize a loss minimization objective, while the agent/model’s design (red base, yellow top) could represent stability (red) and adaptability (yellow).
---
### Interpretation
This diagram represents a **self-improving system** where inference and training are tightly coupled. The hierarchical loss structure in training likely enables the model to learn at multiple scales, while the adaptive classification feedback loop ensures the model refines its predictions iteratively. The stylized agent at the bottom symbolizes the model’s evolving capabilities, shaped by the aggregated loss `L(z)`. The use of color-coded arrows and segmented bars emphasizes modularity and adaptability in both phases.