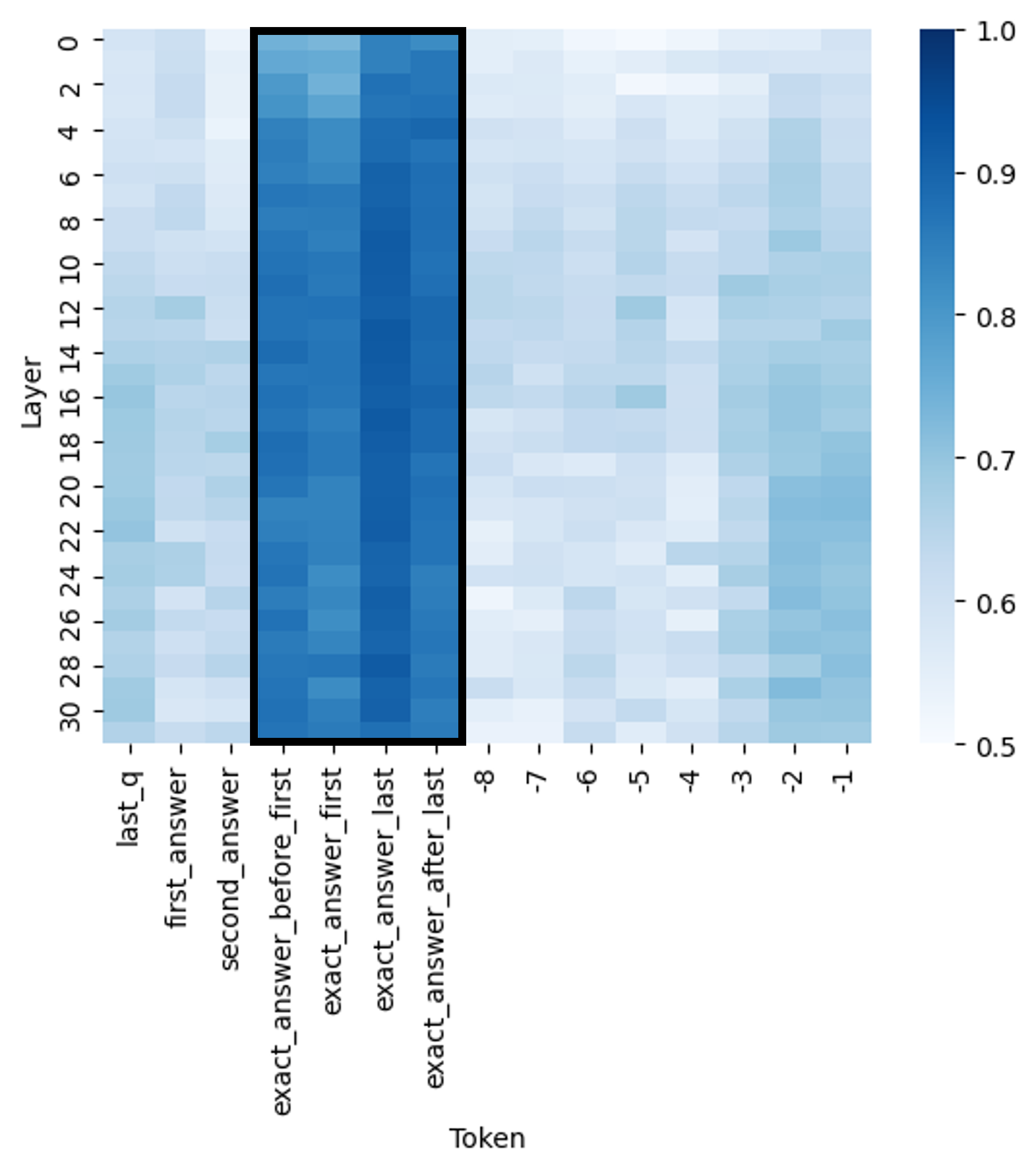
## Heatmap: Attention Weights by Layer and Token
### Overview
The image presents a heatmap visualizing attention weights. The heatmap displays the relationship between layers (vertical axis) and tokens (horizontal axis). The color intensity represents the magnitude of the attention weight, ranging from 0.5 (lightest) to 1.0 (darkest).
### Components/Axes
* **X-axis (Horizontal):** "Token" - Represents different tokens. The tokens are labeled as: "last\_q", "first\_answer", "second\_answer", "exact\_answer\_before\_first", "exact\_answer\_first", "exact\_answer\_last", and tokens numbered -8 to -1.
* **Y-axis (Vertical):** "Layer" - Represents the layer number, ranging from 0 to 30.
* **Color Scale (Right):** Represents the attention weight. The scale ranges from 0.5 (light blue/white) to 1.0 (dark blue).
* **Legend:** Located on the right side of the heatmap, providing a color-to-value mapping for the attention weights.
### Detailed Analysis
The heatmap shows varying attention weights across different layers and tokens.
* **Token "last\_q":** Exhibits high attention weights (close to 1.0) in the initial layers (0-8). The attention decreases as the layer number increases, becoming lighter blue (around 0.6-0.7) in the higher layers (20-30).
* **Token "first\_answer":** Shows a similar trend to "last\_q", with high attention in the lower layers and decreasing attention in the higher layers.
* **Token "second\_answer":** Displays a similar pattern to "first\_answer", with high attention in the lower layers and decreasing attention in the higher layers.
* **Token "exact\_answer\_before\_first":** Shows a moderate attention weight (around 0.7-0.8) across most layers, with a slight increase in attention in the middle layers (10-20).
* **Token "exact\_answer\_first":** Exhibits the highest attention weights (close to 1.0) across a broad range of layers (approximately 4-24). This is the most prominent feature of the heatmap.
* **Token "exact\_answer\_last":** Shows a similar pattern to "exact\_answer\_first", with high attention weights (close to 1.0) across a broad range of layers (approximately 4-24).
* **Tokens -8 to -1:** These tokens generally exhibit lower attention weights (around 0.5-0.7) across all layers, with some slight variations. The attention weights appear to increase slightly in the middle layers (10-20) for some of these tokens.
Here's a more granular breakdown of approximate attention weights at specific layer/token combinations:
* Layer 0, Token "exact\_answer\_first": ~0.95
* Layer 8, Token "exact\_answer\_first": ~0.98
* Layer 16, Token "exact\_answer\_first": ~0.97
* Layer 24, Token "exact\_answer\_first": ~0.95
* Layer 30, Token "exact\_answer\_first": ~0.85
* Layer 0, Token "last\_q": ~0.95
* Layer 30, Token "last\_q": ~0.6
* Layer 0, Token "-8": ~0.55
* Layer 30, Token "-8": ~0.65
### Key Observations
* The tokens "exact\_answer\_first" and "exact\_answer\_last" consistently receive the highest attention weights across a significant portion of the layers.
* The attention weights for "last\_q", "first\_answer", and "second\_answer" decrease as the layer number increases.
* The tokens numbered -8 to -1 generally have lower attention weights compared to the other tokens.
* There is a clear gradient in attention weights, with higher attention in the lower layers and decreasing attention in the higher layers for certain tokens.
### Interpretation
This heatmap likely represents the attention mechanism within a neural network model, possibly a transformer-based model used for question answering or a similar task. The high attention weights assigned to "exact\_answer\_first" and "exact\_answer\_last" suggest that these tokens are crucial for the model's decision-making process, particularly in the middle layers. The decreasing attention weights for "last\_q", "first\_answer", and "second\_answer" as the layer number increases could indicate that the model is refining its focus from the initial query and answers to the final, more precise answer tokens. The lower attention weights for the numbered tokens (-8 to -1) might suggest that these tokens are less relevant to the task or represent contextual information that is not as important as the answer tokens.
The heatmap demonstrates how the model distributes its attention across different parts of the input sequence at different stages of processing. This information can be valuable for understanding the model's behavior, identifying potential biases, and improving its performance. The strong attention on "exact\_answer\_first" and "exact\_answer\_last" suggests the model is heavily reliant on these tokens for making predictions.