## Diagram: Attack Recognition Workflow
### Overview
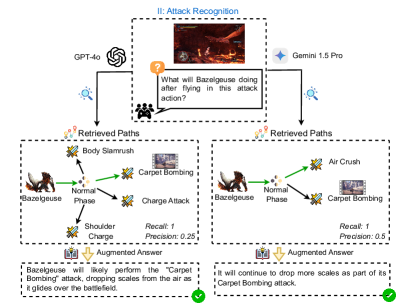
The diagram illustrates a comparative analysis of two AI models (GPT-4o and Gemini 1.5 Pro) in recognizing and predicting attacks performed by the monster "Bazelgeuse" in a game scenario. It includes retrieved attack paths, performance metrics (Recall and Precision), and augmented answers generated by each model.
### Components/Axes
1. **Header**:
- Title: "II: Attack Recognition"
- Central question: "What will Bazelgeuse do after flying in this attack action?"
- Icons: Game controller (player interaction) and question mark (query context).
2. **AI Models**:
- **Left**: GPT-4o (represented by a hexagonal icon).
- **Right**: Gemini 1.5 Pro (represented by a blue diamond icon).
3. **Retrieved Paths**:
- **GPT-4o Paths**:
- Body Slam → Normal Phase → Carpet Bombing
- Charge Attack → Normal Phase → Shoulder Charge
- **Gemini 1.5 Pro Paths**:
- Air Crush → Normal Phase → Carpet Bombing
4. **Metrics**:
- **Recall**: 1 (100%) for both models.
- **Precision**:
- GPT-4o: 0.25 (25%)
- Gemini 1.5 Pro: 0.5 (50%)
5. **Augmented Answers**:
- **GPT-4o**: "Bazelgeuse will likely perform the 'Carpet Bombing' attack, dropping scales from the air as it glides over the battlefield."
- **Gemini 1.5 Pro**: "It will continue to drop more scales as part of its Carpet Bombing attack."
6. **Visual Elements**:
- Arrows indicate flow from AI models to retrieved paths and then to augmented answers.
- Icons (e.g., sword, scales) represent specific attacks.
### Detailed Analysis
- **Retrieved Paths**:
- GPT-4o identifies four attack sequences, including "Shoulder Charge" and "Charge Attack," which are absent in Gemini’s paths.
- Gemini focuses on "Air Crush" as an initial attack, while GPT-4o emphasizes "Body Slam."
- **Metrics**:
- Both models achieve perfect recall (1), indicating they capture all relevant attack sequences.
- Gemini’s higher precision (0.5 vs. 0.25) suggests it is more accurate in predicting the correct attack sequence.
- **Augmented Answers**:
- Both models converge on "Carpet Bombing" as the primary attack but differ in descriptive details (e.g., "dropping scales from the air" vs. "dropping more scales").
### Key Observations
1. **Model Performance**:
- Gemini 1.5 Pro outperforms GPT-4o in precision, suggesting better alignment with the "correct" attack sequence.
- GPT-4o’s lower precision may indicate overgeneralization or inclusion of less relevant attack paths.
2. **Attack Recognition**:
- Both models recognize "Carpet Bombing" as the dominant attack, but their retrieved paths diverge in secondary actions (e.g., "Shoulder Charge" vs. "Air Crush").
3. **Augmented Answers**:
- The answers reflect the models’ retrieved paths, with Gemini’s response being more concise and focused.
### Interpretation
The diagram highlights the trade-off between recall and precision in AI-driven attack recognition. While both models excel at identifying all possible attacks (high recall), Gemini 1.5 Pro demonstrates superior accuracy in predicting the most likely sequence (higher precision). This suggests Gemini may be better suited for scenarios requiring precise action prediction, whereas GPT-4o’s broader attack repertoire could be advantageous in exploratory or creative contexts. The augmented answers demonstrate how each model synthesizes retrieved data into human-readable explanations, with Gemini’s output being more streamlined.
**Note**: No explicit legend is present in the diagram, but color coding (e.g., hexagonal vs. diamond icons) distinguishes the AI models. All textual elements are transcribed as described.