\n
## Diagram: Attack Recognition
### Overview
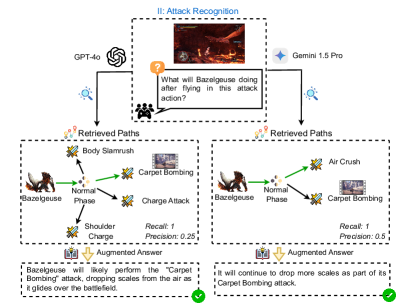
The image presents a comparative diagram illustrating the attack recognition capabilities of two Large Language Models (LLMs): GPT-4o and Gemini 1.5 Pro. The diagram focuses on a scenario involving the character "Bazelgeuse" and attempts to predict its next action after a specific attack phase. The diagram is divided into two main sections, one for each LLM, each showing the retrieved paths and augmented answers.
### Components/Axes
The diagram consists of the following components:
* **Header:** "II: Attack Recognition" with an image of Bazelgeuse in mid-attack.
* **Central Question:** "What will Bazelgeuse doing after flying in this attack action?"
* **LLM Representations:** Two circular icons representing GPT-4o (left) and Gemini 1.5 Pro (right).
* **Retrieved Paths:** Two separate sections, one for each LLM, showing a directed graph of potential attack paths.
* **Nodes:** Representing attack phases (e.g., "Normal Phase", "Charge Attack", "Air Crush").
* **Edges:** Representing transitions between attack phases.
* **Augmented Answer:** Textual responses generated by each LLM.
* **Evaluation Metrics:** "Recall" and "Precision" values associated with each LLM's path.
* **Checkmarks:** Green checkmarks indicating successful predictions.
### Detailed Analysis or Content Details
**GPT-4o Section (Left):**
* **Input:** Bazelgeuse (icon) -> Normal Phase -> Charge Attack -> Shoulder Charge.
* **Intermediate Path:** Bazelgeuse -> Normal Phase -> Carpet Bombing.
* **Recall:** 1
* **Precision:** 0.25
* **Augmented Answer:** "Bazelgeuse will likely perform the 'Carpet Bombing' attack, dropping scales from the air as it glides over the battlefield."
**Gemini 1.5 Pro Section (Right):**
* **Input:** Bazelgeuse (icon) -> Normal Phase -> Air Crush.
* **Intermediate Path:** Bazelgeuse -> Normal Phase -> Carpet Bombing.
* **Recall:** 1
* **Precision:** 0.5
* **Augmented Answer:** "It will continue to drop more scales as part of its 'Carpet Bombing' attack."
**Common Elements:**
* Both LLMs identify "Carpet Bombing" as a likely next attack.
* Both LLMs have a "Recall" of 1.
* The central question is positioned between the two LLM sections.
* The image of Bazelgeuse is positioned at the top center of the diagram.
### Key Observations
* GPT-4o has a lower precision (0.25) compared to Gemini 1.5 Pro (0.5), suggesting that while it correctly identifies the "Carpet Bombing" attack, it has more false positives in its retrieved paths.
* Both models correctly predict the "Carpet Bombing" attack, as indicated by the checkmarks.
* The diagram visually represents the reasoning process of each LLM, showing the different paths considered before arriving at the final answer.
* The intermediate path of "Normal Phase" -> "Carpet Bombing" is common to both models.
### Interpretation
The diagram demonstrates a comparative analysis of two LLMs' ability to recognize and predict attacks in a game context. Both models successfully identify the "Carpet Bombing" attack, but Gemini 1.5 Pro exhibits higher precision, indicating a more refined understanding of the attack patterns. The "Recall" of 1 for both models suggests they are effective at identifying the correct attack when it occurs. The diagram highlights the importance of both recall and precision in evaluating the performance of LLMs in tasks requiring accurate prediction and reasoning. The visual representation of the retrieved paths provides insight into the models' decision-making processes, revealing the different attack sequences considered before arriving at the final answer. The difference in precision suggests that Gemini 1.5 Pro is better at filtering out irrelevant attack paths, leading to a more accurate prediction. The checkmarks serve as a clear indicator of successful predictions, reinforcing the effectiveness of both models in this specific scenario. The diagram suggests that LLMs can be valuable tools for understanding and predicting complex game mechanics.