TECHNICAL ASSET FINGERPRINT
77e2846040ae0fcb674ca4dd
Click to view fullscreen
Press ESC or click to close
FOUND IN PAPERS
EXPERT: gemini-2.0-flash VERSION 1
RUNTIME: nugit/gemini/gemini-2.0-flash
INTEL_VERIFIED
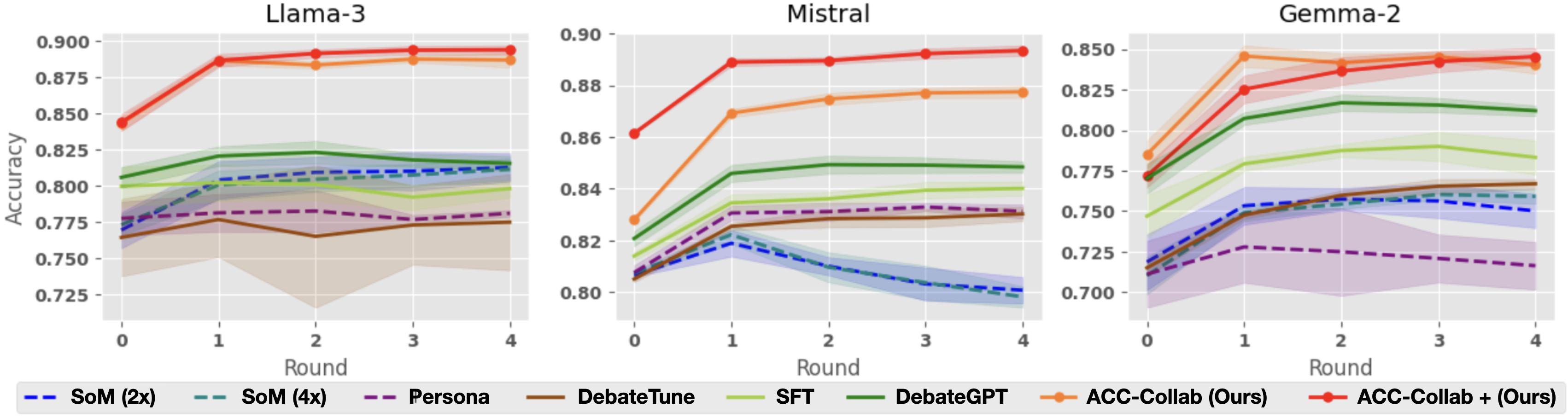
## Chart: Model Accuracy Comparison Across Rounds
### Overview
The image presents three line charts comparing the accuracy of different language models (Llama-3, Mistral, and Gemma-2) across multiple rounds of interaction or training. Each chart displays the performance of several models and training configurations, with accuracy on the y-axis and round number on the x-axis. The legend at the bottom identifies each line by color and label.
### Components/Axes
* **Titles:** Each chart has a title indicating the language model being evaluated: "Llama-3", "Mistral", and "Gemma-2".
* **X-Axis:** Labeled "Round", with integer markers at 0, 1, 2, 3, and 4.
* **Y-Axis:** Labeled "Accuracy", with a scale from 0.725 to 0.900 for Llama-3 and Mistral, and from 0.700 to 0.850 for Gemma-2.
* **Legend:** Located at the bottom of the image, it maps line colors to model/training configurations:
* Blue dashed line: SoM (2x)
* Teal dashed line: SoM (4x)
* Purple dashed line: Persona
* Brown solid line: DebateTune
* Light Green solid line: SFT
* Dark Green solid line: DebateGPT
* Orange solid line: ACC-Collab (Ours)
* Red solid line: ACC-Collab + (Ours)
### Detailed Analysis
#### Llama-3 Chart
* **ACC-Collab + (Ours) (Red):** Starts at approximately 0.845 at Round 0, increases to about 0.890 at Round 1, and then plateaus around 0.890 for Rounds 2-4.
* **ACC-Collab (Ours) (Orange):** Starts at approximately 0.840 at Round 0, increases to about 0.885 at Round 1, and then plateaus around 0.885 for Rounds 2-4.
* **DebateGPT (Dark Green):** Starts at approximately 0.800 at Round 0, increases to about 0.820 at Round 1, and then plateaus around 0.820 for Rounds 2-4.
* **SoM (4x) (Teal):** Starts at approximately 0.780 at Round 0, increases to about 0.815 at Round 1, and then plateaus around 0.815 for Rounds 2-4.
* **SoM (2x) (Blue):** Starts at approximately 0.770 at Round 0, increases to about 0.810 at Round 1, and then plateaus around 0.810 for Rounds 2-4.
* **SFT (Light Green):** Starts at approximately 0.780 at Round 0, increases to about 0.800 at Round 1, and then plateaus around 0.800 for Rounds 2-4.
* **Persona (Purple):** Starts at approximately 0.770 at Round 0, increases to about 0.780 at Round 1, and then plateaus around 0.780 for Rounds 2-4.
* **DebateTune (Brown):** Starts at approximately 0.780 at Round 0, decreases to about 0.760 at Round 1, increases to about 0.780 at Round 2, and then plateaus around 0.780 for Rounds 3-4.
#### Mistral Chart
* **ACC-Collab + (Ours) (Red):** Starts at approximately 0.860 at Round 0, increases to about 0.890 at Round 1, and then plateaus around 0.890 for Rounds 2-4.
* **ACC-Collab (Ours) (Orange):** Starts at approximately 0.830 at Round 0, increases to about 0.870 at Round 1, and then plateaus around 0.875 for Rounds 2-4.
* **DebateGPT (Dark Green):** Starts at approximately 0.830 at Round 0, increases to about 0.850 at Round 1, and then plateaus around 0.850 for Rounds 2-4.
* **SoM (4x) (Teal):** Starts at approximately 0.810 at Round 0, increases to about 0.820 at Round 1, and then decreases to about 0.800 for Rounds 2-4.
* **SoM (2x) (Blue):** Starts at approximately 0.805 at Round 0, increases to about 0.815 at Round 1, and then decreases to about 0.800 for Rounds 2-4.
* **SFT (Light Green):** Starts at approximately 0.815 at Round 0, increases to about 0.830 at Round 1, and then plateaus around 0.830 for Rounds 2-4.
* **Persona (Purple):** Starts at approximately 0.815 at Round 0, increases to about 0.830 at Round 1, and then plateaus around 0.830 for Rounds 2-4.
* **DebateTune (Brown):** Starts at approximately 0.825 at Round 0, increases to about 0.830 at Round 1, and then plateaus around 0.830 for Rounds 2-4.
#### Gemma-2 Chart
* **ACC-Collab + (Ours) (Red):** Starts at approximately 0.770 at Round 0, increases to about 0.840 at Round 1, and then plateaus around 0.840 for Rounds 2-4.
* **ACC-Collab (Ours) (Orange):** Starts at approximately 0.780 at Round 0, increases to about 0.845 at Round 1, and then plateaus around 0.840 for Rounds 2-4.
* **DebateGPT (Dark Green):** Starts at approximately 0.790 at Round 0, increases to about 0.825 at Round 1, and then plateaus around 0.820 for Rounds 2-4.
* **SoM (4x) (Teal):** Starts at approximately 0.720 at Round 0, increases to about 0.760 at Round 1, and then plateaus around 0.760 for Rounds 2-4.
* **SoM (2x) (Blue):** Starts at approximately 0.740 at Round 0, increases to about 0.760 at Round 1, and then plateaus around 0.760 for Rounds 2-4.
* **SFT (Light Green):** Starts at approximately 0.760 at Round 0, increases to about 0.790 at Round 1, and then plateaus around 0.790 for Rounds 2-4.
* **Persona (Purple):** Starts at approximately 0.715 at Round 0, increases to about 0.730 at Round 1, and then plateaus around 0.720 for Rounds 2-4.
* **DebateTune (Brown):** Starts at approximately 0.740 at Round 0, increases to about 0.765 at Round 1, and then plateaus around 0.765 for Rounds 2-4.
### Key Observations
* **ACC-Collab Performance:** The "ACC-Collab + (Ours)" and "ACC-Collab (Ours)" configurations consistently outperform other methods across all three language models.
* **Initial Round Improvement:** Most models show a significant increase in accuracy from Round 0 to Round 1, suggesting that the initial round is crucial for learning or adaptation.
* **Plateau Effect:** After Round 1, the accuracy of most models tends to plateau, indicating diminishing returns from additional rounds.
* **Model-Specific Performance:** The relative performance of different training configurations varies slightly depending on the base language model. For example, the gap between "ACC-Collab" and other methods is more pronounced for Gemma-2 compared to Llama-3.
* **SoM (2x) and SoM (4x) Decline in Mistral:** The accuracy of SoM (2x) and SoM (4x) declines after Round 1 in Mistral.
### Interpretation
The data suggests that the "ACC-Collab" training configurations are highly effective in improving the accuracy of language models, particularly in the initial rounds of interaction or training. The plateau effect observed after Round 1 indicates that there may be a limit to the improvements achievable through the tested methods, or that different strategies are needed to further enhance performance beyond this point. The model-specific variations highlight the importance of tailoring training approaches to the specific characteristics of each language model. The decline of SoM (2x) and SoM (4x) in Mistral suggests that these configurations may not be as well-suited for this particular model.
DECODING INTELLIGENCE...