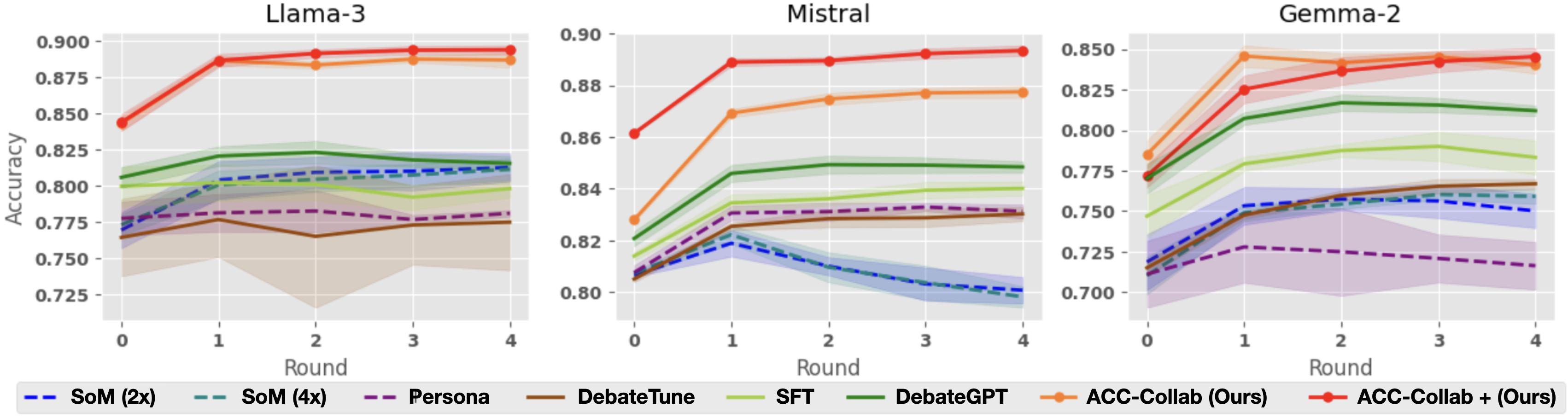
## Line Chart: Accuracy vs. Round for Different Models and Training Methods
### Overview
This image presents three line charts, each displaying the accuracy of different language models (Llama-3, Mistral, and Gemma-2) across four rounds of evaluation. Each chart compares the performance of several training methods: SoM (2x and 4x), Persona, DebateGPT, SFT, DebateTune, and ACC-Collab (Ours) with and without a plus sign. The y-axis represents accuracy, and the x-axis represents the round number.
### Components/Axes
* **X-axis:** Round (0, 1, 2, 3, 4)
* **Y-axis:** Accuracy (ranging approximately from 0.70 to 0.90)
* **Models (Charts):** Llama-3, Mistral, Gemma-2
* **Training Methods (Legend):**
* SoM (2x) - Dashed Blue Line
* SoM (4x) - Dashed Purple Line
* Persona - Solid Blue Line
* DebateGPT - Solid Green Line
* SFT - Solid Orange Line
* DebateTune - Solid Purple Line
* ACC-Collab (Ours) - Solid Orange Line with Marker
* ACC-Collab + (Ours) - Solid Magenta Line with Marker
### Detailed Analysis or Content Details
**Llama-3 Chart:**
* **ACC-Collab (Ours):** Starts at approximately 0.89 accuracy, dips slightly to around 0.87 at round 1, then remains relatively stable around 0.87-0.88 for rounds 2-4.
* **ACC-Collab + (Ours):** Starts at approximately 0.87 accuracy, increases to around 0.88 at round 1, then remains relatively stable around 0.88-0.89 for rounds 2-4.
* **SoM (2x):** Starts at approximately 0.77 accuracy, increases to around 0.81 at round 1, then remains relatively stable around 0.81-0.82 for rounds 2-4.
* **SoM (4x):** Starts at approximately 0.78 accuracy, increases to around 0.82 at round 1, then remains relatively stable around 0.82-0.83 for rounds 2-4.
* **Persona:** Starts at approximately 0.78 accuracy, increases to around 0.81 at round 1, then remains relatively stable around 0.81-0.82 for rounds 2-4.
* **DebateGPT:** Starts at approximately 0.83 accuracy, remains relatively stable around 0.83-0.84 for rounds 1-4.
* **SFT:** Starts at approximately 0.84 accuracy, remains relatively stable around 0.84-0.85 for rounds 1-4.
* **DebateTune:** Starts at approximately 0.82 accuracy, increases to around 0.84 at round 1, then remains relatively stable around 0.84-0.85 for rounds 2-4.
**Mistral Chart:**
* **ACC-Collab (Ours):** Starts at approximately 0.87 accuracy, increases to around 0.89 at round 1, then decreases to around 0.87 at round 4.
* **ACC-Collab + (Ours):** Starts at approximately 0.86 accuracy, increases to around 0.88 at round 1, then decreases to around 0.86 at round 4.
* **SoM (2x):** Starts at approximately 0.80 accuracy, increases to around 0.83 at round 1, then remains relatively stable around 0.83-0.84 for rounds 2-4.
* **SoM (4x):** Starts at approximately 0.81 accuracy, increases to around 0.84 at round 1, then remains relatively stable around 0.84-0.85 for rounds 2-4.
* **Persona:** Starts at approximately 0.81 accuracy, increases to around 0.83 at round 1, then remains relatively stable around 0.83-0.84 for rounds 2-4.
* **DebateGPT:** Starts at approximately 0.84 accuracy, remains relatively stable around 0.84-0.85 for rounds 1-4.
* **SFT:** Starts at approximately 0.85 accuracy, remains relatively stable around 0.85-0.86 for rounds 1-4.
* **DebateTune:** Starts at approximately 0.83 accuracy, increases to around 0.85 at round 1, then remains relatively stable around 0.85-0.86 for rounds 2-4.
**Gemma-2 Chart:**
* **ACC-Collab (Ours):** Starts at approximately 0.81 accuracy, increases to around 0.84 at round 1, then decreases to around 0.82 at round 4.
* **ACC-Collab + (Ours):** Starts at approximately 0.80 accuracy, increases to around 0.83 at round 1, then decreases to around 0.81 at round 4.
* **SoM (2x):** Starts at approximately 0.73 accuracy, increases to around 0.76 at round 1, then remains relatively stable around 0.76-0.77 for rounds 2-4.
* **SoM (4x):** Starts at approximately 0.74 accuracy, increases to around 0.77 at round 1, then remains relatively stable around 0.77-0.78 for rounds 2-4.
* **Persona:** Starts at approximately 0.74 accuracy, increases to around 0.77 at round 1, then remains relatively stable around 0.77-0.78 for rounds 2-4.
* **DebateGPT:** Starts at approximately 0.78 accuracy, remains relatively stable around 0.78-0.79 for rounds 1-4.
* **SFT:** Starts at approximately 0.79 accuracy, remains relatively stable around 0.79-0.80 for rounds 1-4.
* **DebateTune:** Starts at approximately 0.77 accuracy, increases to around 0.79 at round 1, then remains relatively stable around 0.79-0.80 for rounds 2-4.
### Key Observations
* ACC-Collab (Ours) consistently achieves the highest accuracy across all three models, although it shows a slight decrease in accuracy in later rounds for Mistral and Gemma-2.
* SoM (2x) and SoM (4x) generally have the lowest accuracy compared to other training methods.
* DebateGPT and SFT show relatively stable performance across all rounds.
* The addition of "+" to ACC-Collab generally results in slightly higher accuracy, but the difference is minimal.
### Interpretation
The data suggests that the "ACC-Collab (Ours)" training method is the most effective for improving the accuracy of Llama-3, Mistral, and Gemma-2 models. The consistent high performance of this method indicates its robustness and potential for generalization. The slight decrease in accuracy in later rounds for Mistral and Gemma-2 could be due to overfitting or the need for further fine-tuning. The relatively low performance of SoM methods suggests that they may not be as effective for these models or require more extensive training. The stability of DebateGPT and SFT indicates their consistent performance, but they do not reach the same level of accuracy as ACC-Collab. The minimal difference between ACC-Collab and ACC-Collab + suggests that the additional component in the latter may not provide a significant improvement in accuracy. Overall, the data highlights the importance of choosing the right training method to maximize the performance of language models.