TECHNICAL ASSET FINGERPRINT
77e2846040ae0fcb674ca4dd
Click to view fullscreen
Press ESC or click to close
FOUND IN PAPERS
EXPERT: healer-alpha-free VERSION 1
RUNTIME: free/openrouter/healer-alpha
INTEL_VERIFIED
\n
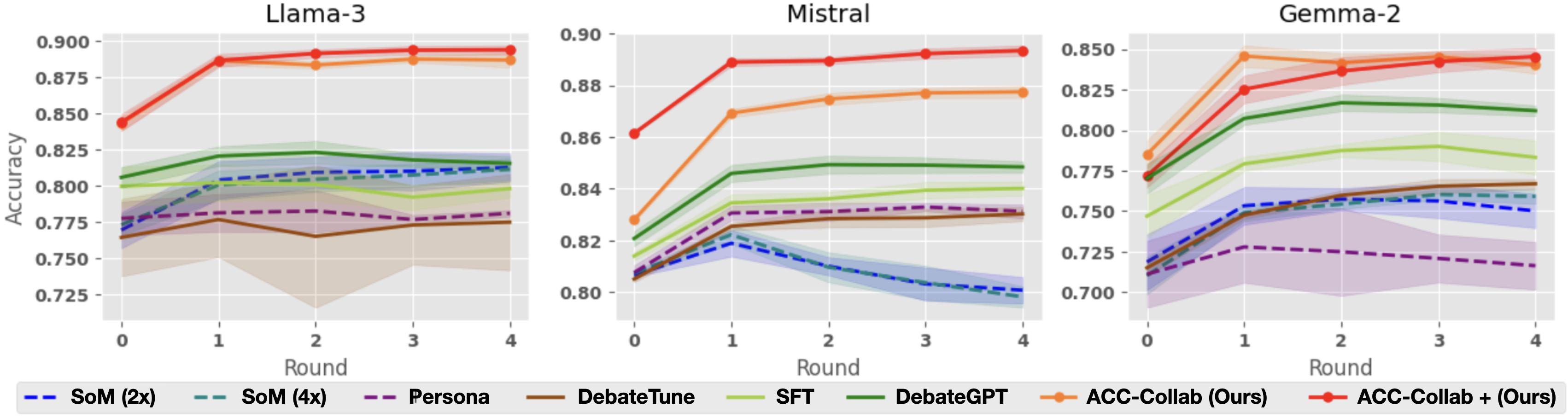
## Line Chart: Accuracy Comparison of AI Models Over Multiple Rounds
### Overview
The image displays three side-by-side line charts comparing the performance (accuracy) of eight different methods or models across five training/evaluation rounds (0 to 4). Each chart corresponds to a different base large language model: Llama-3, Mistral, and Gemma-2. The charts track how the accuracy of each method evolves over successive rounds.
### Components/Axes
* **Chart Titles (Top Center):** "Llama-3", "Mistral", "Gemma-2".
* **Y-Axis (Left Side):** Labeled "Accuracy". The scale varies per chart:
* Llama-3: 0.725 to 0.900 (increments of 0.025).
* Mistral: 0.80 to 0.90 (increments of 0.02).
* Gemma-2: 0.700 to 0.850 (increments of 0.025).
* **X-Axis (Bottom):** Labeled "Round". Markers at 0, 1, 2, 3, 4.
* **Legend (Bottom, spanning all charts):** Contains eight entries, each with a specific color and line style:
1. `SoM (2x)`: Blue dashed line (`--`).
2. `SoM (4x)`: Teal dashed line (`--`).
3. `Persona`: Purple dashed line (`--`).
4. `DebateTune`: Brown solid line.
5. `SFT`: Light green solid line.
6. `DebateGPT`: Dark green solid line.
7. `ACC-Collab (Ours)`: Orange solid line with circular markers.
8. `ACC-Collab + (Ours)`: Red solid line with circular markers.
* **Data Series:** Each method is represented by a line with a shaded region (likely indicating confidence intervals or standard deviation).
### Detailed Analysis
**1. Llama-3 Chart (Left)**
* **Trend Verification:** The two "ACC-Collab" methods (red, orange) show a strong upward trend from Round 0 to 1, then plateau. Other methods show more modest gains or fluctuations.
* **Data Points (Approximate):**
* **ACC-Collab + (Red):** Starts ~0.845 (R0), jumps to ~0.885 (R1), then slowly rises to ~0.895 (R4).
* **ACC-Collab (Orange):** Starts ~0.845 (R0), jumps to ~0.885 (R1), then plateaus around ~0.885-0.890.
* **DebateGPT (Dark Green):** Starts ~0.805 (R0), rises to ~0.820 (R1), peaks ~0.825 (R2), then slightly declines to ~0.815 (R4).
* **SFT (Light Green):** Starts ~0.800 (R0), rises to ~0.805 (R1), then fluctuates around 0.800-0.805.
* **SoM (2x) (Blue Dashed):** Starts ~0.775 (R0), rises to ~0.810 (R1), then slowly increases to ~0.815 (R4).
* **SoM (4x) (Teal Dashed):** Follows a very similar path to SoM (2x), ending slightly lower at ~0.810 (R4).
* **Persona (Purple Dashed):** Starts ~0.775 (R0), rises to ~0.785 (R1), then remains flat around 0.780-0.785.
* **DebateTune (Brown):** Starts ~0.765 (R0), rises to ~0.775 (R1), dips to ~0.765 (R2), then recovers to ~0.775 (R4).
**2. Mistral Chart (Center)**
* **Trend Verification:** Similar pattern where ACC-Collab methods lead. Notably, the SoM methods (blue, teal dashed) show a clear peak at Round 1 followed by a significant decline.
* **Data Points (Approximate):**
* **ACC-Collab + (Red):** Starts ~0.860 (R0), jumps to ~0.890 (R1), then slowly rises to ~0.895 (R4).
* **ACC-Collab (Orange):** Starts ~0.830 (R0), jumps to ~0.870 (R1), then rises to ~0.875 (R4).
* **DebateGPT (Dark Green):** Starts ~0.820 (R0), rises to ~0.845 (R1), then plateaus around ~0.850.
* **SFT (Light Green):** Starts ~0.815 (R0), rises to ~0.835 (R1), then slowly increases to ~0.840 (R4).
* **Persona (Purple Dashed):** Starts ~0.810 (R0), rises to ~0.830 (R1), then plateaus around ~0.830.
* **DebateTune (Brown):** Starts ~0.805 (R0), rises to ~0.825 (R1), then slowly increases to ~0.830 (R4).
* **SoM (2x) (Blue Dashed):** Starts ~0.805 (R0), peaks at ~0.820 (R1), then declines sharply to ~0.800 (R4).
* **SoM (4x) (Teal Dashed):** Follows a nearly identical path to SoM (2x), peaking at ~0.820 (R1) and declining to ~0.800 (R4).
**3. Gemma-2 Chart (Right)**
* **Trend Verification:** ACC-Collab methods again show strong initial gains. The DebateGPT (dark green) line shows a distinct peak at Round 2 before declining.
* **Data Points (Approximate):**
* **ACC-Collab (Orange):** Starts ~0.785 (R0), jumps to ~0.845 (R1), then plateaus around ~0.840-0.845.
* **ACC-Collab + (Red):** Starts ~0.770 (R0), jumps to ~0.825 (R1), then rises to ~0.845 (R4).
* **DebateGPT (Dark Green):** Starts ~0.770 (R0), rises to ~0.810 (R1), peaks at ~0.820 (R2), then declines to ~0.810 (R4).
* **SFT (Light Green):** Starts ~0.745 (R0), rises to ~0.780 (R1), then slowly increases to ~0.790 (R4).
* **DebateTune (Brown):** Starts ~0.715 (R0), rises to ~0.750 (R1), then slowly increases to ~0.770 (R4).
* **SoM (2x) (Blue Dashed):** Starts ~0.720 (R0), rises to ~0.755 (R1), then plateaus around ~0.755-0.760.
* **SoM (4x) (Teal Dashed):** Follows a similar path to SoM (2x), ending slightly lower at ~0.755 (R4).
* **Persona (Purple Dashed):** Starts ~0.710 (R0), rises to ~0.725 (R1), then slowly declines to ~0.720 (R4).
### Key Observations
1. **Consistent Superiority:** The methods labeled "ACC-Collab (Ours)" and "ACC-Collab + (Ours)" (orange and red lines) consistently achieve the highest accuracy across all three base models (Llama-3, Mistral, Gemma-2) by the final round.
2. **Strong Initial Gains:** All methods show their most significant accuracy improvement between Round 0 and Round 1.
3. **Model-Specific Behavior:**
* On **Mistral**, the SoM methods (2x and 4x) exhibit a unique "peak and decline" pattern, performing best at Round 1 but degrading afterward.
* On **Gemma-2**, the DebateGPT method shows a clear performance peak at Round 2 before declining.
4. **Performance Clustering:** Methods tend to cluster in performance tiers. The ACC-Collab variants form the top tier. DebateGPT and SFT often form a middle tier. The remaining methods (SoM variants, Persona, DebateTune) generally occupy the lower tier, though their relative ordering varies by model.
5. **Uncertainty Bands:** The shaded regions indicate variability in performance. The bands are generally wider for lower-performing methods (e.g., DebateTune on Llama-3) and narrower for the top-performing ACC-Collab methods, suggesting more consistent results.
### Interpretation
This data strongly suggests that the proposed "ACC-Collab" methods (both the standard and "+" variants) are more effective at improving and sustaining accuracy over multiple rounds of debate or collaboration compared to the baseline methods (SoM, Persona, DebateTune, SFT, DebateGPT). The consistent top-tier performance across three distinct LLM architectures (Llama, Mistral, Gemma) indicates the robustness of the ACC-Collab approach.
The "peak and decline" behavior of some methods (SoM on Mistral, DebateGPT on Gemma-2) is a critical finding. It suggests these methods may suffer from issues like overfitting to early rounds, catastrophic forgetting, or an inability to leverage later rounds effectively. In contrast, the ACC-Collab methods show stable or improving performance after the initial jump, indicating a more sustainable learning or adaptation process.
The charts collectively demonstrate that the choice of collaboration/finetuning method has a larger impact on final accuracy than the choice of base model within this set, as the performance hierarchy of methods is largely preserved across the three different models. The research appears to validate the authors' "ACC-Collab" technique as a superior method for multi-round collaborative AI tasks.
DECODING INTELLIGENCE...