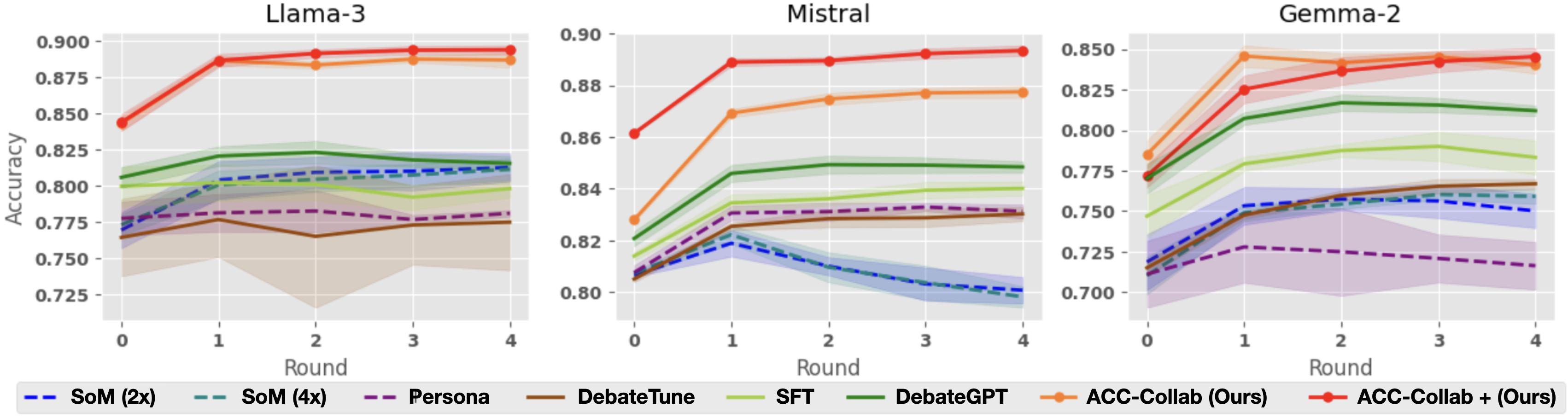
## Line Graphs: Model Performance Across Rounds (Llama-3, Mistral, Gemma-2)
### Overview
Three line graphs compare the accuracy of different AI models (Llama-3, Mistral, Gemma-2) across four training rounds. Each graph includes multiple data series representing distinct training methods, with shaded regions indicating confidence intervals. The graphs emphasize the performance of "ACC-Collab (Ours)" and "ACC-Collab + (Ours)" methods relative to baseline approaches.
### Components/Axes
- **X-axis**: "Round" (0 to 4), representing training iterations.
- **Y-axis**: "Accuracy" (0.725 to 0.900), measured as a decimal.
- **Legends**: Positioned at the bottom of each graph, mapping colors and line styles to methods:
- **Solid lines**: Primary methods (e.g., ACC-Collab).
- **Dashed lines**: Alternative configurations (e.g., ACC-Collab +).
- **Shaded regions**: Confidence intervals (lighter versions of line colors).
### Detailed Analysis
#### Llama-3
- **ACC-Collab (Ours)** (red solid): Starts at ~0.845 (Round 0), rises steadily to ~0.895 (Round 4).
- **ACC-Collab + (Ours)** (orange solid): Begins at ~0.875, plateaus near ~0.885.
- **SoM (2x)** (blue dashed): Declines from ~0.775 to ~0.765.
- **DebateGPT** (green solid): Peaks at ~0.825 (Round 2), then declines to ~0.815.
- **Confidence intervals**: Widest for SoM (2x) and DebateGPT, narrowest for ACC-Collab methods.
#### Mistral
- **ACC-Collab (Ours)** (red solid): Jumps from ~0.86 to ~0.885 by Round 1, stabilizes.
- **ACC-Collab + (Ours)** (orange solid): Starts at ~0.87, rises to ~0.885.
- **SoM (4x)** (teal dashed): Drops sharply from ~0.82 to ~0.79.
- **Persona** (purple dashed): Flat at ~0.78.
- **Confidence intervals**: SoM (4x) shows high variability (wide shaded area).
#### Gemma-2
- **ACC-Collab (Ours)** (red solid): Rises from ~0.80 to ~0.88.
- **ACC-Collab + (Ours)** (orange solid): Starts at ~0.82, peaks at ~0.885.
- **DebateTune** (brown dashed): Gradual increase from ~0.76 to ~0.79.
- **SFT** (yellow solid): Stable at ~0.79.
- **Confidence intervals**: ACC-Collab methods have tighter bands than DebateTune.
### Key Observations
1. **ACC-Collab Dominance**: In all models, ACC-Collab methods outperform baselines, especially in later rounds.
2. **Convergence**: ACC-Collab + (Ours) often matches or slightly exceeds ACC-Collab (Ours), suggesting incremental improvements.
3. **Declining Baselines**: SoM (2x/4x) and DebateGPT show performance drops after initial rounds, indicating potential overfitting or instability.
4. **Gemma-2 Volatility**: DebateTune’s wide confidence intervals suggest inconsistent training outcomes.
### Interpretation
The data demonstrates that **ACC-Collab methods** (both variants) are robust across models, with performance gains correlating with training rounds. The shaded regions highlight that methods like SoM (4x) and DebateGPT suffer from higher uncertainty, possibly due to complex training dynamics. ACC-Collab + (Ours) appears to refine the base ACC-Collab approach, offering marginal but consistent improvements. Notably, Gemma-2’s DebateTune method exhibits the most variability, raising questions about its training stability. These trends suggest that collaborative training frameworks (ACC-Collab) may better balance accuracy and reliability compared to isolated methods.