\n
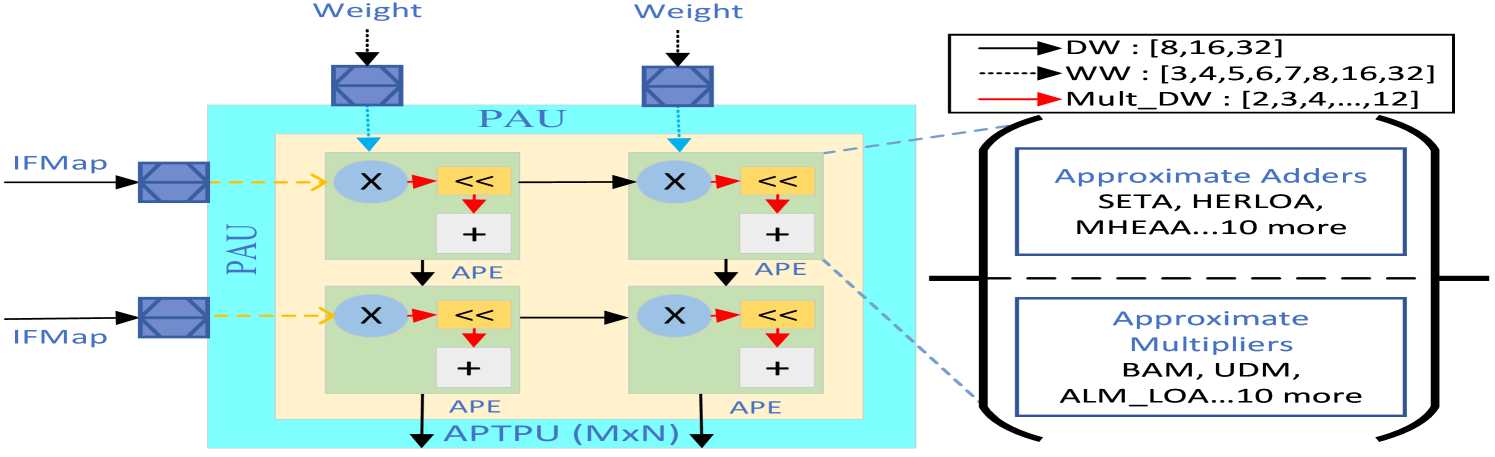
## Diagram: APTPU (Approximate Processing Tensor Processing Unit) Architecture
### Overview
The image is a technical block diagram illustrating the architecture of an APTPU (Approximate Processing Tensor Processing Unit), specifically a Processing Array Unit (PAU) composed of multiple Approximate Processing Elements (APEs). The diagram details the data flow for input feature maps (IFMap) and weights, the internal operations within an APE, and the configurable data widths for different operations. It also lists example approximate arithmetic components.
### Components/Axes
**Main Block: PAU (Processing Array Unit)**
* A large, light blue rectangle labeled "PAU" at the top center.
* Inside the PAU is a smaller, light yellow rectangle representing the core processing array.
* The entire structure is labeled "APTPU (MxN)" at the bottom center, indicating a scalable M-by-N array of processing elements.
**Inputs (Left Side):**
* Two inputs labeled "IFMap" (Input Feature Map) enter from the left. Each is represented by a blue, textured square block.
* Two inputs labeled "Weight" enter from the top. Each is represented by a similar blue, textured square block.
**Processing Elements (APEs):**
* The core contains four identical blocks arranged in a 2x2 grid, each labeled "APE" (Approximate Processing Element) at its bottom-right corner.
* **Internal APE Components:** Each APE contains:
* A blue circle with an "X" (Multiplier).
* A yellow rectangle with "<<" (Left Shift operation).
* A white rectangle with a "+" (Adder).
* Red arrows connect the multiplier to the shifter, and the shifter to the adder.
* Black arrows show data flow between APEs horizontally and vertically.
**Legend (Top-Right):**
* A black-bordered box contains a legend defining arrow types and data widths.
* **Solid Black Arrow:** Labeled "DW : [8,16,32]" (Data Width).
* **Dashed Black Arrow:** Labeled "WW : [3,4,5,6,7,8,16,32]" (Weight Width).
* **Solid Red Arrow:** Labeled "Mult_DW : [2,3,4,...,12]" (Multiplier Data Width).
**Annotation Box (Right Side):**
* A large, black-bordered bracket points from the legend to two blue-bordered boxes on the right.
* **Top Box:** Titled "Approximate Adders". Lists examples: "SETA, HERLOA, MHEAA...10 more".
* **Bottom Box:** Titled "Approximate Multipliers". Lists examples: "BAM, UDM, ALM_LOA...10 more".
### Detailed Analysis
**Data Flow and Connections:**
1. **IFMap Path:** The two "IFMap" inputs (left) connect via dashed yellow lines to the multipliers in the left column of APEs.
2. **Weight Path:** The two "Weight" inputs (top) connect via dashed blue lines to the multipliers in the top row of APEs.
3. **Internal APE Flow:** Within each APE:
* The multiplier (X) receives one input from the IFMap path and one from the Weight path.
* The multiplier's output (red arrow) goes to the left shift operation (<<).
* The shifter's output (red arrow) goes to the adder (+).
4. **Inter-APE Flow:**
* Horizontal black arrows connect the adder of a left APE to the multiplier of the APE to its right.
* Vertical black arrows connect the adder of a top APE to the multiplier of the APE below it.
* This creates a systolic or dataflow pattern for accumulation.
**Legend & Data Width Specifics:**
* **DW (Data Width):** Configurable to 8, 16, or 32 bits. This likely applies to the main data paths (IFMap, intermediate results).
* **WW (Weight Width):** Highly configurable, with options from 3 to 32 bits. This allows for precision scaling of the weight parameters.
* **Mult_DW (Multiplier Data Width):** Ranges from 2 to 12 bits. This is a key feature of approximate computing, allowing the use of lower-precision, more efficient multipliers.
**Approximate Components:**
* The diagram explicitly states that the APEs can be implemented using various approximate adder and multiplier designs.
* It provides three named examples for each category (SETA, HERLOA, MHEAA for adders; BAM, UDM, ALM_LOA for multipliers) and indicates there are "10 more" of each type available, suggesting a library of approximate arithmetic units.
### Key Observations
1. **Modular and Scalable Design:** The "APTPU (MxN)" label and the 2x2 APE grid imply the architecture is designed to be scaled by adding more APEs in a mesh.
2. **Precision Flexibility:** The system supports a wide range of data and weight precisions (DW, WW, Mult_DW), enabling trade-offs between computational accuracy, energy efficiency, and hardware cost.
3. **Explicit Approximate Computing:** The core innovation is the integration of "Approximate Adders" and "Approximate Multipliers" directly into the processing element's data path, as highlighted by the dedicated annotation box.
4. **Dataflow Architecture:** The connection pattern between APEs (horizontal and vertical accumulation) is characteristic of a systolic array or a similar dataflow architecture optimized for matrix/tensor operations common in neural networks.
### Interpretation
This diagram describes a hardware accelerator designed for **approximate computing**, specifically targeted at tensor processing tasks like those in neural network inference. The core idea is to replace exact arithmetic units with approximate ones (e.g., SETA adders, BAM multipliers) to achieve significant gains in power efficiency and performance at the cost of controlled, minor computational errors.
The configurable data widths (DW, WW, Mult_DW) are crucial knobs for managing this accuracy-efficiency trade-off. For instance, using a 4-bit multiplier (Mult_DW) on 8-bit data (DW) would drastically reduce hardware complexity compared to a standard 8x8 multiplier. The listed approximate components (SETA, BAM, etc.) represent specific circuit-level designs that implement these approximate functions.
The architecture's value lies in its flexibility. It allows a system designer to select, for each layer or operation in a neural network, the most efficient combination of approximate adders and multipliers and the lowest viable precision, thereby optimizing the hardware for a specific accuracy target and workload. The "10 more" note suggests this is a modular framework where different approximate arithmetic libraries can be plugged into the same APE template.