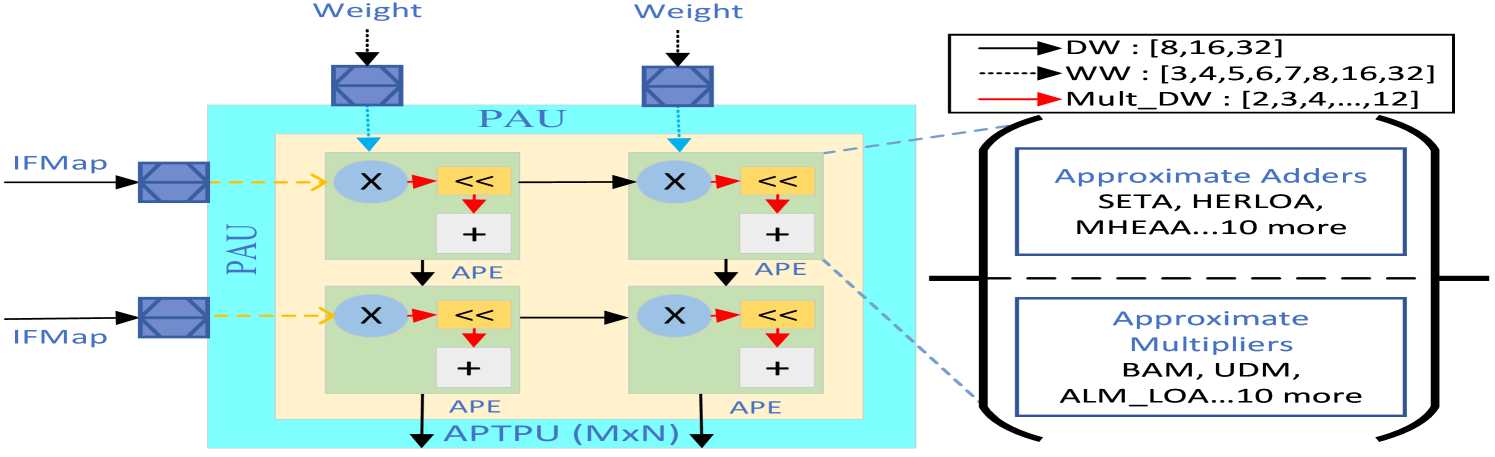
## Block Diagram: Processing Array Unit (PAU) Architecture
### Overview
The diagram illustrates a computational architecture for a Processing Array Unit (PAU) with data flow between Input Feature Maps (IFMaps), Processing Elements (APEs), and an Approximate Processing Tensor Unit (APTU). The system emphasizes approximate arithmetic operations for efficiency, with specialized components for adders and multipliers.
### Components/Axes
**Legend (Right Side):**
- **Weight Types:**
- DW: [8,16,32] (Dotted black line)
- WW: [3,4,5,6,7,8,16,32] (Dashed black line)
- Mult_DW: [2,3,4,...,12] (Solid red line)
- **Approximate Adders:** SETA, HERLOA, MHEAA (10 more examples)
- **Approximate Multipliers:** BAM, UDM, ALM_LOA (10 more examples)
**Main Diagram Elements:**
1. **IFMaps (Input Feature Maps):**
- Two input blocks (dashed yellow arrows) feeding into PAU
- Positioned left of PAU
2. **PAU (Processing Array Unit):**
- Central blue box containing:
- Four APE blocks (green squares)
- Internal operations:
- `X <<` (bit-shift operation)
- `+` (addition)
- Connected to APTU via `APTU (MxN)` arrow
3. **APTU (Approximate Processing Tensor Unit):**
- Bottom of PAU block
- Receives aggregated output from APEs
**Data Flow:**
- IFMaps → PAU → APEs → APTU
- Weight inputs feed into PAU from top
### Detailed Analysis
**Weight Configuration:**
- DW (8/16/32-bit weights) likely represent standard precision
- WW (3-8/16/32-bit weights) suggest variable-width quantization
- Mult_DW (2-12-bit weights) indicate specialized multiplication units
**Approximate Arithmetic Units:**
- Adders: 12+ specialized units (SETA, HERLOA, MHEAA)
- Multipliers: 12+ specialized units (BAM, UDM, ALM_LOA)
- Positioned in separate boxes, suggesting hardware acceleration
**Processing Flow:**
1. IFMaps provide input data to PAU
2. PAU processes data through four parallel APEs
3. Each APE performs:
- Bit-shift operation (`X <<`)
- Addition (`+`)
4. Results aggregate in APTU (MxN matrix operations)
### Key Observations
1. **Modular Design:**
- Clear separation between input (IFMaps), processing (PAU/APEs), and output (APTU)
- Parallel APE architecture enables concurrent operations
2. **Approximation Focus:**
- 22+ specialized approximate units (adders/multipliers)
- Suggests power/energy efficiency optimization
3. **Weight Flexibility:**
- Multiple weight formats (DW/WW/Mult_DW) indicate support for:
- Quantized neural network models
- Mixed-precision computations
4. **Matrix Operations:**
- APTU's MxN configuration implies tensor/matrix multiplication capabilities
- Critical for deep learning operations
### Interpretation
This architecture appears designed for:
1. **Edge AI Acceleration:**
- Approximate arithmetic reduces power consumption
- Specialized units optimize for neural network operations
2. **Quantized Model Support:**
- Multiple weight formats (DW/WW/Mult_DW) enable:
- 8-bit/16-bit/32-bit fixed-point operations
- Variable-width quantization for different layers
3. **Efficient Data Flow:**
- Direct IFMap → PAU → APTU pathway minimizes latency
- APE parallelism enables high throughput
4. **Hardware-Software Co-Design:**
- Approximate adders/multipliers suggest custom silicon
- Balances accuracy (standard operations) with efficiency (approximate units)
The diagram reveals a sophisticated computational engine optimized for:
- Low-power neural network inference
- Mixed-precision computations
- High-throughput matrix operations
- Customizable weight handling through multiple formats