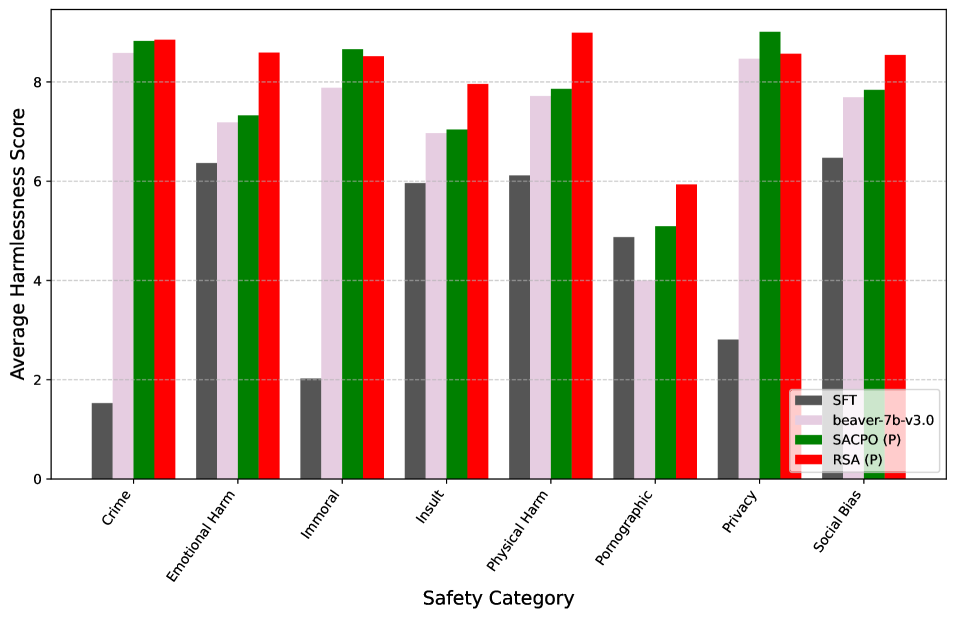
## Bar Chart: Average Harmlessness Scores Across Safety Categories
### Overview
The chart compares the average harmlessness scores of four AI safety models (SFT, beaver-7b-v3.0, SACPO (P), and RSA (P)) across eight safety categories. Scores range from 0 to 9, with higher values indicating greater harmlessness. The chart uses grouped bars to visualize performance differences between models within each category.
### Components/Axes
- **X-axis**: Safety Categories (Crime, Emotional Harm, Immoral, Insult, Physical Harm, Pornographic, Privacy, Social Bias)
- **Y-axis**: Average Harmlessness Score (0–9)
- **Legend**:
- Dark gray: SFT
- Light purple: beaver-7b-v3.0
- Green: SACPO (P)
- Red: RSA (P)
- **Bar Structure**: Four bars per category, ordered left-to-right as per legend
### Detailed Analysis
1. **Crime**
- SFT: ~1.5
- beaver-7b-v3.0: ~8.5
- SACPO (P): ~8.8
- RSA (P): ~8.9
2. **Emotional Harm**
- SFT: ~6.3
- beaver-7b-v3.0: ~7.2
- SACPO (P): ~7.4
- RSA (P): ~8.6
3. **Immoral**
- SFT: ~2.0
- beaver-7b-v3.0: ~7.9
- SACPO (P): ~8.7
- RSA (P): ~8.5
4. **Insult**
- SFT: ~6.0
- beaver-7b-v3.0: ~7.0
- SACPO (P): ~7.1
- RSA (P): ~8.0
5. **Physical Harm**
- SFT: ~6.1
- beaver-7b-v3.0: ~7.7
- SACPO (P): ~7.9
- RSA (P): ~9.0
6. **Pornographic**
- SFT: ~4.8
- beaver-7b-v3.0: ~4.0
- SACPO (P): ~5.0
- RSA (P): ~6.0
7. **Privacy**
- SFT: ~2.8
- beaver-7b-v3.0: ~8.5
- SACPO (P): ~9.0
- RSA (P): ~8.6
8. **Social Bias**
- SFT: ~6.5
- beaver-7b-v3.0: ~7.7
- SACPO (P): ~7.9
- RSA (P): ~8.6
### Key Observations
- **RSA (P)** consistently achieves the highest scores across most categories, particularly in Crime (~8.9) and Physical Harm (~9.0).
- **SFT** shows the lowest performance, especially in Crime (~1.5) and Immoral (~2.0), with moderate scores in other categories.
- **beaver-7b-v3.0** performs well in most categories but struggles in Pornographic (~4.0) and Immoral (~7.9).
- **SACPO (P)** demonstrates strong performance in Immoral (~8.7) and Privacy (~9.0), with moderate scores in other categories.
- **Pornographic** category shows the largest performance gap between models (~4.0 for beaver-7b-v3.0 vs. ~6.0 for RSA (P)).
### Interpretation
The data suggests significant variability in model robustness across safety categories:
1. **RSA (P)** appears to be the most robust model overall, with near-perfect scores in high-risk categories like Crime and Physical Harm.
2. **SFT** exhibits critical weaknesses in foundational safety categories (Crime, Immoral), indicating potential design limitations.
3. **beaver-7b-v3.0** shows mixed performance, excelling in general safety but failing in specialized categories like Pornographic content.
4. **SACPO (P)** demonstrates category-specific strengths, particularly in Immoral and Privacy contexts, suggesting targeted training effectiveness.
Notable anomalies include:
- SFT's extreme underperformance in Crime (~1.5 vs. ~8.9 for RSA (P))
- beaver-7b-v3.0's significant drop in Pornographic content (~4.0 vs. ~8.6 for RSA (P))
- SACPO (P)'s near-perfect Privacy score (~9.0) contrasting with its moderate Social Bias score (~7.9)
These patterns highlight the importance of category-specific evaluation in AI safety development, as no single model achieves consistent high performance across all safety dimensions.