TECHNICAL ASSET FINGERPRINT
785241960937d14ad0499c1a
Click to view fullscreen
Press ESC or click to close
FOUND IN PAPERS
EXPERT: gemini-2.0-flash VERSION 1
RUNTIME: nugit/gemini/gemini-2.0-flash
INTEL_VERIFIED
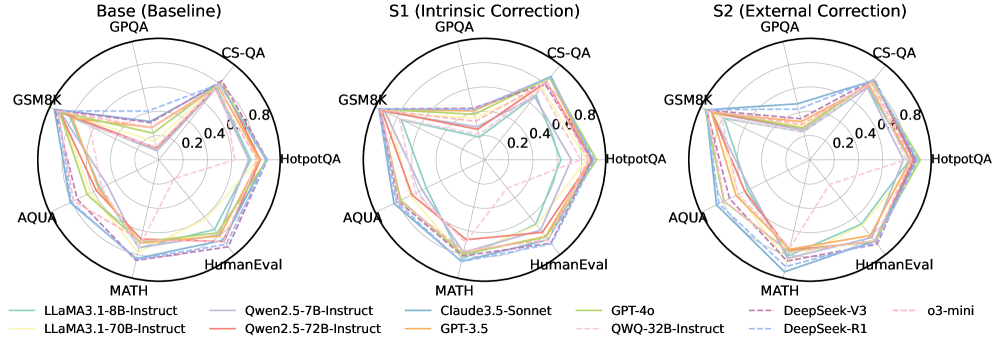
## Radar Charts: Model Performance on GPQA Benchmarks
### Overview
The image presents three radar charts comparing the performance of various language models on the GPQA benchmark, across different settings: a baseline model (Base), a model with intrinsic correction (S1), and a model with external correction (S2). Each chart visualizes the performance of multiple models across several tasks, including CS-QA, GSM8K, HotpotQA, AQUA, HumanEval, and MATH.
### Components/Axes
* **Chart Type**: Radar Charts (3 charts side-by-side)
* **Titles**:
* Left Chart: "Base (Baseline) GPQA"
* Middle Chart: "S1 (Intrinsic Correction) GPQA"
* Right Chart: "S2 (External Correction) GPQA"
* **Axes**:
* Radial Axis: Represents performance score, ranging from 0.0 to 0.8, with markers at 0.2, 0.4, 0.6, 0.8.
* Angular Axis: Represents different tasks/benchmarks: CS-QA, GSM8K, HotpotQA, AQUA, HumanEval, MATH. These are arranged clockwise around the circle.
* **Legend**: Located at the bottom of the image. Lists the models and their corresponding line colors:
* Light Blue: LLaMA3.1-8B-Instruct
* Light Yellow: LLaMA3.1-70B-Instruct
* Light Purple: Qwen2.5-7B-Instruct
* Light Red: Qwen2.5-72B-Instruct
* Darker Blue: Claude3.5-Sonnet
* Orange: GPT-3.5
* Green: GPT-4o
* Dashed Light Purple: QWQ-32B-Instruct
* Dashed Dark Blue: DeepSeek-V3
* Dashed Light Blue: DeepSeek-R1
* Dashed Light Pink: o3-mini
### Detailed Analysis or ### Content Details
**Chart 1: Base (Baseline) GPQA**
* **LLaMA3.1-8B-Instruct (Light Blue)**: Scores approximately 0.6 on CS-QA, 0.7 on GSM8K, 0.5 on HotpotQA, 0.4 on AQUA, 0.3 on HumanEval, and 0.2 on MATH.
* **LLaMA3.1-70B-Instruct (Light Yellow)**: Scores approximately 0.7 on CS-QA, 0.75 on GSM8K, 0.6 on HotpotQA, 0.5 on AQUA, 0.4 on HumanEval, and 0.3 on MATH.
* **Qwen2.5-7B-Instruct (Light Purple)**: Scores approximately 0.7 on CS-QA, 0.75 on GSM8K, 0.6 on HotpotQA, 0.5 on AQUA, 0.4 on HumanEval, and 0.3 on MATH.
* **Qwen2.5-72B-Instruct (Light Red)**: Scores approximately 0.7 on CS-QA, 0.8 on GSM8K, 0.6 on HotpotQA, 0.5 on AQUA, 0.4 on HumanEval, and 0.3 on MATH.
* **Claude3.5-Sonnet (Darker Blue)**: Scores approximately 0.7 on CS-QA, 0.8 on GSM8K, 0.6 on HotpotQA, 0.5 on AQUA, 0.4 on HumanEval, and 0.3 on MATH.
* **GPT-3.5 (Orange)**: Scores approximately 0.7 on CS-QA, 0.75 on GSM8K, 0.6 on HotpotQA, 0.5 on AQUA, 0.4 on HumanEval, and 0.3 on MATH.
* **GPT-4o (Green)**: Scores approximately 0.7 on CS-QA, 0.8 on GSM8K, 0.6 on HotpotQA, 0.5 on AQUA, 0.4 on HumanEval, and 0.3 on MATH.
* **QWQ-32B-Instruct (Dashed Light Purple)**: Scores approximately 0.6 on CS-QA, 0.7 on GSM8K, 0.5 on HotpotQA, 0.4 on AQUA, 0.3 on HumanEval, and 0.2 on MATH.
* **DeepSeek-V3 (Dashed Dark Blue)**: Scores approximately 0.7 on CS-QA, 0.75 on GSM8K, 0.6 on HotpotQA, 0.5 on AQUA, 0.4 on HumanEval, and 0.3 on MATH.
* **DeepSeek-R1 (Dashed Light Blue)**: Scores approximately 0.7 on CS-QA, 0.75 on GSM8K, 0.6 on HotpotQA, 0.5 on AQUA, 0.4 on HumanEval, and 0.3 on MATH.
* **o3-mini (Dashed Light Pink)**: Scores approximately 0.5 on CS-QA, 0.6 on GSM8K, 0.4 on HotpotQA, 0.3 on AQUA, 0.2 on HumanEval, and 0.1 on MATH.
**Chart 2: S1 (Intrinsic Correction) GPQA**
* **LLaMA3.1-8B-Instruct (Light Blue)**: Scores approximately 0.7 on CS-QA, 0.8 on GSM8K, 0.6 on HotpotQA, 0.5 on AQUA, 0.4 on HumanEval, and 0.3 on MATH.
* **LLaMA3.1-70B-Instruct (Light Yellow)**: Scores approximately 0.7 on CS-QA, 0.8 on GSM8K, 0.6 on HotpotQA, 0.5 on AQUA, 0.4 on HumanEval, and 0.3 on MATH.
* **Qwen2.5-7B-Instruct (Light Purple)**: Scores approximately 0.7 on CS-QA, 0.8 on GSM8K, 0.6 on HotpotQA, 0.5 on AQUA, 0.4 on HumanEval, and 0.3 on MATH.
* **Qwen2.5-72B-Instruct (Light Red)**: Scores approximately 0.7 on CS-QA, 0.8 on GSM8K, 0.6 on HotpotQA, 0.5 on AQUA, 0.4 on HumanEval, and 0.3 on MATH.
* **Claude3.5-Sonnet (Darker Blue)**: Scores approximately 0.7 on CS-QA, 0.8 on GSM8K, 0.6 on HotpotQA, 0.5 on AQUA, 0.4 on HumanEval, and 0.3 on MATH.
* **GPT-3.5 (Orange)**: Scores approximately 0.7 on CS-QA, 0.8 on GSM8K, 0.6 on HotpotQA, 0.5 on AQUA, 0.4 on HumanEval, and 0.3 on MATH.
* **GPT-4o (Green)**: Scores approximately 0.8 on CS-QA, 0.85 on GSM8K, 0.7 on HotpotQA, 0.6 on AQUA, 0.5 on HumanEval, and 0.4 on MATH.
* **QWQ-32B-Instruct (Dashed Light Purple)**: Scores approximately 0.7 on CS-QA, 0.8 on GSM8K, 0.6 on HotpotQA, 0.5 on AQUA, 0.4 on HumanEval, and 0.3 on MATH.
* **DeepSeek-V3 (Dashed Dark Blue)**: Scores approximately 0.7 on CS-QA, 0.8 on GSM8K, 0.6 on HotpotQA, 0.5 on AQUA, 0.4 on HumanEval, and 0.3 on MATH.
* **DeepSeek-R1 (Dashed Light Blue)**: Scores approximately 0.7 on CS-QA, 0.8 on GSM8K, 0.6 on HotpotQA, 0.5 on AQUA, 0.4 on HumanEval, and 0.3 on MATH.
* **o3-mini (Dashed Light Pink)**: Scores approximately 0.6 on CS-QA, 0.7 on GSM8K, 0.5 on HotpotQA, 0.4 on AQUA, 0.3 on HumanEval, and 0.2 on MATH.
**Chart 3: S2 (External Correction) GPQA**
* **LLaMA3.1-8B-Instruct (Light Blue)**: Scores approximately 0.7 on CS-QA, 0.8 on GSM8K, 0.6 on HotpotQA, 0.5 on AQUA, 0.4 on HumanEval, and 0.3 on MATH.
* **LLaMA3.1-70B-Instruct (Light Yellow)**: Scores approximately 0.7 on CS-QA, 0.8 on GSM8K, 0.6 on HotpotQA, 0.5 on AQUA, 0.4 on HumanEval, and 0.3 on MATH.
* **Qwen2.5-7B-Instruct (Light Purple)**: Scores approximately 0.7 on CS-QA, 0.8 on GSM8K, 0.6 on HotpotQA, 0.5 on AQUA, 0.4 on HumanEval, and 0.3 on MATH.
* **Qwen2.5-72B-Instruct (Light Red)**: Scores approximately 0.7 on CS-QA, 0.8 on GSM8K, 0.6 on HotpotQA, 0.5 on AQUA, 0.4 on HumanEval, and 0.3 on MATH.
* **Claude3.5-Sonnet (Darker Blue)**: Scores approximately 0.7 on CS-QA, 0.8 on GSM8K, 0.6 on HotpotQA, 0.5 on AQUA, 0.4 on HumanEval, and 0.3 on MATH.
* **GPT-3.5 (Orange)**: Scores approximately 0.7 on CS-QA, 0.8 on GSM8K, 0.6 on HotpotQA, 0.5 on AQUA, 0.4 on HumanEval, and 0.3 on MATH.
* **GPT-4o (Green)**: Scores approximately 0.8 on CS-QA, 0.9 on GSM8K, 0.7 on HotpotQA, 0.6 on AQUA, 0.5 on HumanEval, and 0.4 on MATH.
* **QWQ-32B-Instruct (Dashed Light Purple)**: Scores approximately 0.7 on CS-QA, 0.8 on GSM8K, 0.6 on HotpotQA, 0.5 on AQUA, 0.4 on HumanEval, and 0.3 on MATH.
* **DeepSeek-V3 (Dashed Dark Blue)**: Scores approximately 0.7 on CS-QA, 0.8 on GSM8K, 0.6 on HotpotQA, 0.5 on AQUA, 0.4 on HumanEval, and 0.3 on MATH.
* **DeepSeek-R1 (Dashed Light Blue)**: Scores approximately 0.7 on CS-QA, 0.8 on GSM8K, 0.6 on HotpotQA, 0.5 on AQUA, 0.4 on HumanEval, and 0.3 on MATH.
* **o3-mini (Dashed Light Pink)**: Scores approximately 0.6 on CS-QA, 0.7 on GSM8K, 0.5 on HotpotQA, 0.4 on AQUA, 0.3 on HumanEval, and 0.2 on MATH.
### Key Observations
* **Task Performance**: Models generally perform best on GSM8K and CS-QA, and worst on MATH and HumanEval.
* **Model Comparison**: GPT-4o (Green) consistently shows higher performance across all tasks and settings compared to other models. o3-mini (Dashed Light Pink) generally performs the worst.
* **Correction Impact**: Intrinsic (S1) and External (S2) corrections generally improve performance compared to the baseline (Base), with S2 showing a slight edge over S1.
### Interpretation
The radar charts provide a visual comparison of language model performance across different question-answering tasks. The data suggests that:
* **Task Difficulty**: Some tasks are inherently more challenging for these models, as evidenced by the consistently lower scores on MATH and HumanEval.
* **Model Superiority**: GPT-4o demonstrates superior performance, indicating its advanced capabilities in handling diverse question types.
* **Effectiveness of Corrections**: Both intrinsic and external correction methods enhance model performance, suggesting that these techniques are valuable for improving accuracy and reliability. The slight advantage of external correction (S2) may indicate that providing additional context or information during the correction process is beneficial.
* **Model Consistency**: The relative performance of models remains consistent across different correction settings. Models that perform well in the baseline setting tend to maintain their relative advantage in the corrected settings.
DECODING INTELLIGENCE...
EXPERT: nemotron-free VERSION 1
RUNTIME: free/nvidia/nemotron-nano-12b-v2-vl:free
INTEL_VERIFIED
## Radar Chart: Model Performance Across Evaluation Metrics
### Overview
The image contains three horizontally aligned radar charts comparing the performance of multiple AI models across seven evaluation metrics: GPQA, CS-QA, HotpotQA, GSM8K, AQUA, MATH, and HumanEval. Each chart represents a different evaluation framework: "Base (Baseline)", "S1 (Intrinsic Correction)", and "S2 (External Correction)". The charts use a circular layout with radial axes scaled from 0.2 to 0.8, and models are represented by colored lines connecting their scores across metrics.
### Components/Axes
- **Radial Axes**:
- GPQA (top)
- CS-QA (top-right)
- HotpotQA (right)
- GSM8K (bottom-right)
- AQUA (bottom)
- MATH (bottom-left)
- HumanEval (left)
- **Legends**:
- **Base (Baseline)**:
- LLaMA3.1-8B-Instruct (teal)
- Qwen2.5-7B-Instruct (purple)
- Claude3.5-Sonnet (blue)
- GPT-4o (green)
- DeepSeek-V3 (dark purple)
- o3-mini (pink)
- **S1 (Intrinsic Correction)**:
- LLaMA3.1-70B-Instruct (yellow)
- Qwen2.5-72B-Instruct (orange)
- GPT-3.5 (red)
- QWQ-32B-Instruct (dashed pink)
- DeepSeek-R1 (dashed blue)
- **S2 (External Correction)**: Same models as S1 but with updated performance values.
- **Scale**: Radial axes marked at 0.2, 0.4, 0.6, 0.8.
### Detailed Analysis
#### Base (Baseline)
- **LLaMA3.1-8B-Instruct** (teal): Peaks at GPQA (~0.75), lowest in MATH (~0.45).
- **Qwen2.5-7B-Instruct** (purple): Strong in CS-QA (~0.7), weaker in GSM8K (~0.55).
- **Claude3.5-Sonnet** (blue): Balanced performance, highest in HumanEval (~0.7).
- **GPT-4o** (green): Highest in MATH (~0.75), moderate in GPQA (~0.65).
- **DeepSeek-V3** (dark purple): Strong in CS-QA (~0.7), lower in AQUA (~0.5).
- **o3-mini** (pink): Highest in HumanEval (~0.75), lowest in GSM8K (~0.5).
#### S1 (Intrinsic Correction)
- **LLaMA3.1-70B-Instruct** (yellow): Improved in MATH (~0.7), slight drop in GPQA (~0.65).
- **Qwen2.5-72B-Instruct** (orange): Increased CS-QA (~0.75), stable HumanEval (~0.65).
- **GPT-3.5** (red): Minimal changes, peaks in AQUA (~0.6).
- **QWQ-32B-Instruct** (dashed pink): New entry, strong in CS-QA (~0.7), weak in MATH (~0.4).
- **DeepSeek-R1** (dashed blue): Improved HumanEval (~0.7), slight drop in GSM8K (~0.55).
#### S2 (External Correction)
- **LLaMA3.1-70B-Instruct** (yellow): Further gains in MATH (~0.75), stable GPQA (~0.65).
- **Qwen2.5-72B-Instruct** (orange): CS-QA peaks at ~0.8, HumanEval drops to ~0.6.
- **GPT-3.5** (red): Slight improvement in AQUA (~0.65).
- **QWQ-32B-Instruct** (dashed pink): CS-QA remains ~0.7, MATH improves to ~0.45.
- **DeepSeek-R1** (dashed blue): HumanEval peaks at ~0.75, GSM8K drops to ~0.5.
### Key Observations
1. **Model Specialization**:
- GPT-4o and LLaMA3.1-70B-Instruct dominate MATH.
- Qwen2.5-72B-Instruct and DeepSeek-R1 excel in CS-QA and HumanEval.
2. **Correction Impact**:
- S1 and S2 show mixed results: Some models improve in specific metrics (e.g., Qwen2.5-72B-Instruct in CS-QA) while others decline (e.g., LLaMA3.1-70B-Instruct in GPQA).
- External correction (S2) amplifies performance gaps between models.
3. **Outliers**:
- o3-mini underperforms in GSM8K across all frameworks.
- QWQ-32B-Instruct shows inconsistent results, excelling in CS-QA but struggling in MATH.
### Interpretation
The charts suggest that correction frameworks (S1/S2) do not universally improve model performance. Instead, gains in one metric (e.g., CS-QA for Qwen2.5-72B-Instruct) often come at the cost of others (e.g., HumanEval). The baseline models (Base) exhibit more balanced performance, while larger models (e.g., LLaMA3.1-70B-Instruct) show greater specialization. The data implies that correction methods may introduce trade-offs, highlighting the need for context-specific evaluation. Notably, HumanEval scores remain relatively stable across frameworks, suggesting it is less sensitive to correction techniques compared to task-specific metrics like MATH or CS-QA.
DECODING INTELLIGENCE...