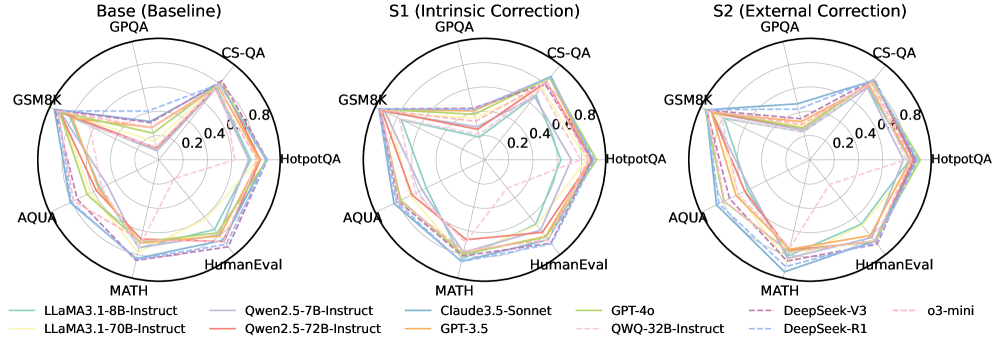
## Radar Charts: Model Performance Comparison Across Benchmarks
### Overview
The image presents three radar charts comparing the performance of several language models across six different benchmarks: GSM8K, MATH, HumanEval, HotpotQA, CS-QA, and AQUA. Each chart represents a different evaluation setting: "Base (Baseline) GPQA", "S1 (Intrinsic Correction) GPQA", and "S2 (External Correction) GPQA". The performance is measured on a scale from approximately 0 to 0.8, indicated by concentric circles. Each line on the radar chart represents a different language model.
### Components/Axes
* **Benchmarks (Axes):** GSM8K, MATH, HumanEval, HotpotQA, CS-QA, AQUA. These are evenly spaced around the circular charts.
* **Radial Scale:** The scale ranges from approximately 0.0 to 0.8, with markings at 0.2, 0.4, 0.6, and 0.8.
* **Models (Lines):**
* LLaMA3.1-8B-Instruct (Dark Blue, dashed)
* LLaMA3.1-70B-Instruct (Dark Blue, solid)
* Owen2.5-7B-Instruct (Orange)
* Owen2.5-72B-Instruct (Pink)
* Claude3.5-Sonnet (Green)
* GPT-3.5 (Light Orange)
* GPT-4o (Light Green)
* QWQ-32B-Instruct (Cyan)
* DeepSeek-V3 (Purple, dashed)
* DeepSeek-R1 (Purple, solid)
* o3-mini (Red)
* **Titles:** Each chart has a title indicating the evaluation setting: "Base (Baseline) GPQA", "S1 (Intrinsic Correction) GPQA", "S2 (External Correction) GPQA".
* **Legend:** Located at the bottom of the image, the legend maps each color and line style to a specific language model.
### Detailed Analysis or Content Details
**Base (Baseline) GPQA:**
* **LLaMA3.1-8B-Instruct (Dark Blue, dashed):** Shows relatively low performance across all benchmarks, with a peak around 0.3-0.4 for CS-QA and GSM8K.
* **LLaMA3.1-70B-Instruct (Dark Blue, solid):** Performs better than the 8B version, peaking around 0.5-0.6 for CS-QA and GSM8K.
* **Owen2.5-7B-Instruct (Orange):** Exhibits moderate performance, peaking around 0.4 for GSM8K and CS-QA.
* **Owen2.5-72B-Instruct (Pink):** Shows higher performance than the 7B version, peaking around 0.5-0.6 for GSM8K and CS-QA.
* **Claude3.5-Sonnet (Green):** Performs well, peaking around 0.6-0.7 for GSM8K and CS-QA.
* **GPT-3.5 (Light Orange):** Shows moderate performance, peaking around 0.4-0.5 for GSM8K and CS-QA.
* **GPT-4o (Light Green):** Exhibits the highest performance, peaking around 0.7-0.8 for GSM8K and CS-QA.
* **QWQ-32B-Instruct (Cyan):** Shows moderate performance, peaking around 0.4-0.5 for GSM8K and CS-QA.
* **DeepSeek-V3 (Purple, dashed):** Exhibits moderate performance, peaking around 0.4-0.5 for GSM8K and CS-QA.
* **DeepSeek-R1 (Purple, solid):** Shows higher performance than the V3 version, peaking around 0.5-0.6 for GSM8K and CS-QA.
* **o3-mini (Red):** Shows relatively low performance across all benchmarks, peaking around 0.3-0.4 for CS-QA and GSM8K.
**S1 (Intrinsic Correction) GPQA:**
* The overall trend is similar to the "Base" chart, but most models show slightly improved performance. GPT-4o continues to lead, and the LLaMA models show modest gains.
* The performance differences between the models are more pronounced in this setting.
**S2 (External Correction) GPQA:**
* Again, the trend is similar to the "Base" chart, with most models showing slightly improved performance. GPT-4o remains the top performer.
* The performance differences between the models are further amplified in this setting.
### Key Observations
* GPT-4o consistently outperforms all other models across all benchmarks and evaluation settings.
* Larger models (e.g., 70B versions of LLaMA and Owen) generally perform better than their smaller counterparts (e.g., 8B and 7B versions).
* The "Intrinsic Correction" (S1) and "External Correction" (S2) methods generally lead to slight performance improvements across most models.
* The performance variations across benchmarks are significant. Models tend to perform better on GSM8K and CS-QA compared to HumanEval and AQUA.
### Interpretation
The radar charts demonstrate the relative strengths and weaknesses of different language models across a variety of challenging benchmarks. The consistent dominance of GPT-4o suggests its superior capabilities in reasoning, knowledge, and problem-solving. The performance gains observed with the "Intrinsic Correction" and "External Correction" methods indicate that these techniques can effectively enhance model performance. The varying performance across benchmarks highlights the importance of evaluating models on a diverse set of tasks to obtain a comprehensive understanding of their capabilities. The charts suggest that model size is a significant factor in performance, but other factors, such as model architecture and training data, also play a crucial role. The differences in performance between the models could be attributed to variations in their training data, model architecture, and optimization strategies. The data suggests that the GPQA framework, with and without corrections, is a useful tool for evaluating and comparing the performance of language models.