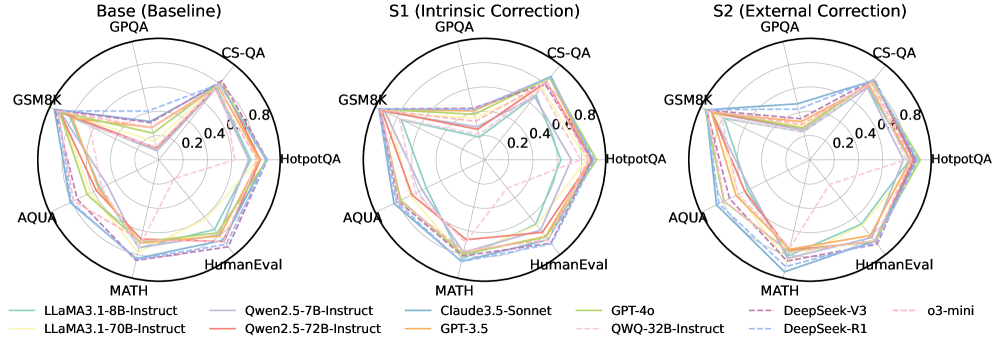
## Radar Chart: Model Performance Across Evaluation Metrics
### Overview
The image contains three horizontally aligned radar charts comparing the performance of multiple AI models across seven evaluation metrics: GPQA, CS-QA, HotpotQA, GSM8K, AQUA, MATH, and HumanEval. Each chart represents a different evaluation framework: "Base (Baseline)", "S1 (Intrinsic Correction)", and "S2 (External Correction)". The charts use a circular layout with radial axes scaled from 0.2 to 0.8, and models are represented by colored lines connecting their scores across metrics.
### Components/Axes
- **Radial Axes**:
- GPQA (top)
- CS-QA (top-right)
- HotpotQA (right)
- GSM8K (bottom-right)
- AQUA (bottom)
- MATH (bottom-left)
- HumanEval (left)
- **Legends**:
- **Base (Baseline)**:
- LLaMA3.1-8B-Instruct (teal)
- Qwen2.5-7B-Instruct (purple)
- Claude3.5-Sonnet (blue)
- GPT-4o (green)
- DeepSeek-V3 (dark purple)
- o3-mini (pink)
- **S1 (Intrinsic Correction)**:
- LLaMA3.1-70B-Instruct (yellow)
- Qwen2.5-72B-Instruct (orange)
- GPT-3.5 (red)
- QWQ-32B-Instruct (dashed pink)
- DeepSeek-R1 (dashed blue)
- **S2 (External Correction)**: Same models as S1 but with updated performance values.
- **Scale**: Radial axes marked at 0.2, 0.4, 0.6, 0.8.
### Detailed Analysis
#### Base (Baseline)
- **LLaMA3.1-8B-Instruct** (teal): Peaks at GPQA (~0.75), lowest in MATH (~0.45).
- **Qwen2.5-7B-Instruct** (purple): Strong in CS-QA (~0.7), weaker in GSM8K (~0.55).
- **Claude3.5-Sonnet** (blue): Balanced performance, highest in HumanEval (~0.7).
- **GPT-4o** (green): Highest in MATH (~0.75), moderate in GPQA (~0.65).
- **DeepSeek-V3** (dark purple): Strong in CS-QA (~0.7), lower in AQUA (~0.5).
- **o3-mini** (pink): Highest in HumanEval (~0.75), lowest in GSM8K (~0.5).
#### S1 (Intrinsic Correction)
- **LLaMA3.1-70B-Instruct** (yellow): Improved in MATH (~0.7), slight drop in GPQA (~0.65).
- **Qwen2.5-72B-Instruct** (orange): Increased CS-QA (~0.75), stable HumanEval (~0.65).
- **GPT-3.5** (red): Minimal changes, peaks in AQUA (~0.6).
- **QWQ-32B-Instruct** (dashed pink): New entry, strong in CS-QA (~0.7), weak in MATH (~0.4).
- **DeepSeek-R1** (dashed blue): Improved HumanEval (~0.7), slight drop in GSM8K (~0.55).
#### S2 (External Correction)
- **LLaMA3.1-70B-Instruct** (yellow): Further gains in MATH (~0.75), stable GPQA (~0.65).
- **Qwen2.5-72B-Instruct** (orange): CS-QA peaks at ~0.8, HumanEval drops to ~0.6.
- **GPT-3.5** (red): Slight improvement in AQUA (~0.65).
- **QWQ-32B-Instruct** (dashed pink): CS-QA remains ~0.7, MATH improves to ~0.45.
- **DeepSeek-R1** (dashed blue): HumanEval peaks at ~0.75, GSM8K drops to ~0.5.
### Key Observations
1. **Model Specialization**:
- GPT-4o and LLaMA3.1-70B-Instruct dominate MATH.
- Qwen2.5-72B-Instruct and DeepSeek-R1 excel in CS-QA and HumanEval.
2. **Correction Impact**:
- S1 and S2 show mixed results: Some models improve in specific metrics (e.g., Qwen2.5-72B-Instruct in CS-QA) while others decline (e.g., LLaMA3.1-70B-Instruct in GPQA).
- External correction (S2) amplifies performance gaps between models.
3. **Outliers**:
- o3-mini underperforms in GSM8K across all frameworks.
- QWQ-32B-Instruct shows inconsistent results, excelling in CS-QA but struggling in MATH.
### Interpretation
The charts suggest that correction frameworks (S1/S2) do not universally improve model performance. Instead, gains in one metric (e.g., CS-QA for Qwen2.5-72B-Instruct) often come at the cost of others (e.g., HumanEval). The baseline models (Base) exhibit more balanced performance, while larger models (e.g., LLaMA3.1-70B-Instruct) show greater specialization. The data implies that correction methods may introduce trade-offs, highlighting the need for context-specific evaluation. Notably, HumanEval scores remain relatively stable across frameworks, suggesting it is less sensitive to correction techniques compared to task-specific metrics like MATH or CS-QA.