\n
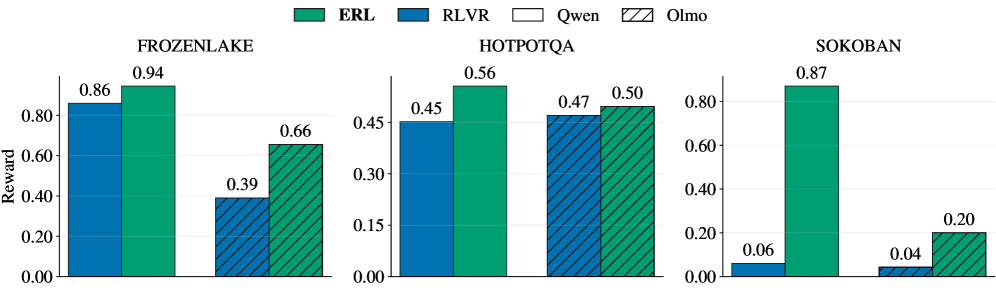
## Bar Chart: Reward Comparison Across Environments
### Overview
The image presents a bar chart comparing the reward achieved by four different algorithms (ERL, RLVR, Qwen, and Olmo) across three distinct environments: FrozenLake, HotpotQA, and Sokoban. The reward is represented on the y-axis, while the x-axis represents the different algorithms within each environment.
### Components/Axes
* **Y-axis:** Labeled "Reward", with a scale ranging from 0.00 to 1.00, incrementing by 0.20.
* **X-axis:** Represents the algorithms being compared within each environment.
* **Environments:** Three environments are displayed: FrozenLake, HotpotQA, and Sokoban, each with its own set of bars.
* **Legend:** Located at the top-left corner, identifying the algorithms by color:
* ERL (Green)
* RLVR (Blue)
* Qwen (Light Green)
* Olmo (Purple)
### Detailed Analysis
**FrozenLake:**
* ERL: The green bar for ERL in FrozenLake reaches approximately 0.94.
* RLVR: The blue bar for RLVR in FrozenLake reaches approximately 0.86.
* Qwen: The light green bar for Qwen in FrozenLake reaches approximately 0.39.
* Olmo: The purple bar for Olmo in FrozenLake reaches approximately 0.66.
**HotpotQA:**
* ERL: The green bar for ERL in HotpotQA reaches approximately 0.56.
* RLVR: The blue bar for RLVR in HotpotQA reaches approximately 0.45.
* Qwen: The light green bar for Qwen in HotpotQA reaches approximately 0.47.
* Olmo: The purple bar for Olmo in HotpotQA reaches approximately 0.50.
**Sokoban:**
* ERL: The green bar for ERL in Sokoban reaches approximately 0.87.
* RLVR: The blue bar for RLVR in Sokoban reaches approximately 0.06.
* Qwen: The light green bar for Qwen in Sokoban reaches approximately 0.20.
* Olmo: The purple bar for Olmo in Sokoban reaches approximately 0.04.
### Key Observations
* ERL consistently achieves high rewards across all three environments, often the highest.
* RLVR performs well in FrozenLake and HotpotQA, but significantly underperforms in Sokoban.
* Qwen's performance is moderate across all environments.
* Olmo's performance is variable, with moderate performance in FrozenLake and HotpotQA, but very low performance in Sokoban.
* Sokoban appears to be the most challenging environment, as the reward values are generally lower compared to FrozenLake and HotpotQA.
### Interpretation
The data suggests that the ERL algorithm is the most robust and effective across the tested environments. It consistently achieves the highest rewards, indicating its ability to learn and perform well in diverse problem settings. RLVR demonstrates good performance in simpler environments like FrozenLake and HotpotQA, but struggles with the complexity of Sokoban. Qwen provides a moderate level of performance, while Olmo's performance is inconsistent.
The significant difference in reward values across environments highlights the varying difficulty levels of the tasks. Sokoban, with its lower reward values, likely presents a more complex challenge for the algorithms, requiring more sophisticated learning strategies. The comparison of these algorithms provides valuable insights into their strengths and weaknesses, guiding future research and development efforts in reinforcement learning. The data suggests that algorithm performance is highly environment-dependent, and a single algorithm may not be optimal for all tasks.