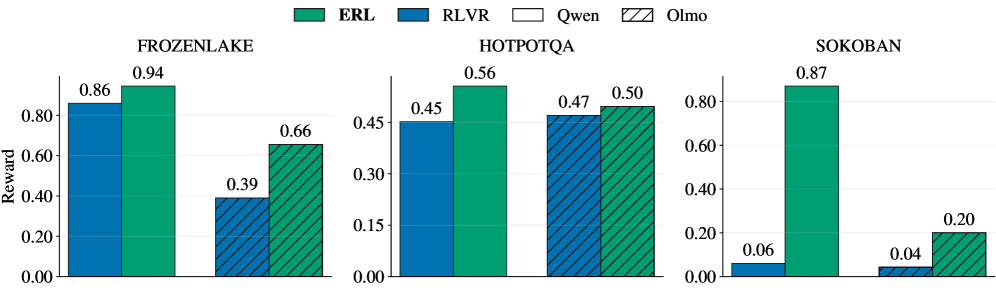
## Bar Chart: Reward Comparison Across Environments
### Overview
The image is a grouped bar chart comparing the performance of four methods (ERL, RLVR, Qwen, Olmo) across three environments (FROZENLAKE, HOTPOTQA, SOKOBAN). Rewards are measured on a scale from 0.00 to 0.90. Each environment is represented by a cluster of four bars, with distinct colors and patterns for each method.
### Components/Axes
- **X-axis**: Environment names (FROZENLAKE, HOTPOTQA, SOKOBAN), evenly spaced.
- **Y-axis**: Reward values (0.00 to 0.90 in increments of 0.10).
- **Legend**: Located at the top, mapping colors/patterns to methods:
- **ERL**: Solid green
- **RLVR**: Solid blue
- **Qwen**: Solid white
- **Olmo**: Diagonal striped (black/gray)
- **Bar Groups**: Each environment has four bars, ordered left-to-right as per the legend.
### Detailed Analysis
#### FROZENLAKE
- **ERL**: 0.94 (highest, solid green)
- **RLVR**: 0.86 (solid blue)
- **Qwen**: 0.66 (solid white)
- **Olmo**: 0.39 (striped)
#### HOTPOTQA
- **ERL**: 0.56 (solid green)
- **RLVR**: 0.45 (solid blue)
- **Qwen**: 0.47 (solid white)
- **Olmo**: 0.50 (striped)
#### SOKOBAN
- **ERL**: 0.87 (solid green)
- **RLVR**: 0.06 (solid blue)
- **Qwen**: 0.04 (solid white)
- **Olmo**: 0.20 (striped)
### Key Observations
1. **ERL Dominance**: ERL achieves the highest reward in all three environments, with particularly strong performance in SOKOBAN (0.87).
2. **Olmo Variability**: Olmo outperforms other methods in HOTPOTQA (0.50) but underperforms in FROZENLAKE (0.39) and SOKOBAN (0.20).
3. **RLVR Decline**: RLVR shows a sharp drop in SOKOBAN (0.06 vs. 0.45 in HOTPOTQA), suggesting poor adaptation to this environment.
4. **Qwen Consistency**: Qwen maintains moderate performance (0.47–0.66) but never leads.
### Interpretation
The data indicates that **ERL is the most robust method**, consistently achieving the highest rewards across diverse environments. **Olmo’s performance is context-dependent**, excelling in HOTPOTQA but struggling in others. **RLVR and Qwen** exhibit lower overall effectiveness, with RLVR’s drastic drop in SOKOBAN highlighting potential limitations in handling complex tasks. The stark contrast in SOKOBAN rewards (ERL: 0.87 vs. RLVR/Qwen: 0.04–0.06) suggests significant methodological differences in addressing this environment’s challenges.