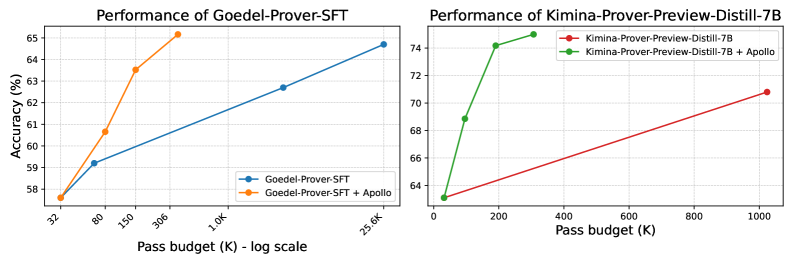
## Line Charts: Performance of Language Models
### Overview
The image presents two line charts comparing the performance (Accuracy in %) of different language models against varying "Pass budget" (in thousands, K) on a logarithmic scale for the first chart. The first chart focuses on "Goedel-SFT" and "Goedel-SFT + Apollo", while the second chart focuses on "Kimina-Prover-Preview-Distill-7B" and "Kimina-Prover-Preview-Distill-7B + Apollo".
### Components/Axes
**Chart 1: Performance of Goedel-SFT**
* **X-axis:** Pass budget (K) - log scale. Markers at 32, 80, 150, 306, 1.0k, 25.6k.
* **Y-axis:** Accuracy (%) - Scale from approximately 58% to 65%.
* **Legend:**
* Blue Line: Goedel-Prover-SFT
* Orange Line: Goedel-Prover-SFT + Apollo
**Chart 2: Performance of Kimina-Prover-Preview-Distill-7B**
* **X-axis:** Pass budget (K) - Scale from 0 to 1000. Markers at 0, 200, 400, 600, 800, 1000.
* **Y-axis:** Accuracy (%) - Scale from approximately 64% to 75%.
* **Legend:**
* Red Line: Kimina-Prover-Preview-Distill-7B
* Green Line: Kimina-Prover-Preview-Distill-7B + Apollo
### Detailed Analysis or Content Details
**Chart 1: Goedel-SFT Performance**
* **Goedel-Prover-SFT (Blue Line):** The line slopes upward, indicating increasing accuracy with increasing pass budget.
* At 32K: Approximately 58.5% accuracy.
* At 80K: Approximately 60.2% accuracy.
* At 150K: Approximately 61.8% accuracy.
* At 306K: Approximately 62.5% accuracy.
* At 1.0K: Approximately 62.7% accuracy.
* At 25.6K: Approximately 64.5% accuracy.
* **Goedel-Prover-SFT + Apollo (Orange Line):** The line initially rises sharply, then plateaus.
* At 32K: Approximately 63.5% accuracy.
* At 80K: Approximately 64.2% accuracy.
* At 150K: Approximately 65.0% accuracy.
* At 306K: Approximately 65.2% accuracy.
* At 1.0K: Approximately 65.1% accuracy.
* At 25.6K: Approximately 65.0% accuracy.
**Chart 2: Kimina-Prover-Preview-Distill-7B Performance**
* **Kimina-Prover-Preview-Distill-7B (Red Line):** The line slopes upward, but at a decreasing rate.
* At 0K: Approximately 64.2% accuracy.
* At 200K: Approximately 68.5% accuracy.
* At 400K: Approximately 69.5% accuracy.
* At 600K: Approximately 69.8% accuracy.
* At 800K: Approximately 70.0% accuracy.
* At 1000K: Approximately 70.2% accuracy.
* **Kimina-Prover-Preview-Distill-7B + Apollo (Green Line):** The line rises sharply initially, then plateaus at a higher accuracy than the base model.
* At 0K: Approximately 71.5% accuracy.
* At 200K: Approximately 74.2% accuracy.
* At 400K: Approximately 74.5% accuracy.
* At 600K: Approximately 74.4% accuracy.
* At 800K: Approximately 74.3% accuracy.
* At 1000K: Approximately 74.2% accuracy.
### Key Observations
* For both models, adding "Apollo" consistently improves accuracy, especially at lower pass budgets.
* The improvement from "Apollo" diminishes as the pass budget increases, suggesting a point of diminishing returns.
* The Goedel-SFT model shows a more consistent improvement with increasing pass budget compared to the Kimina model.
* The Kimina model with Apollo starts at a significantly higher accuracy than the Goedel model with Apollo.
### Interpretation
The charts demonstrate the impact of "Pass budget" and the "Apollo" enhancement on the accuracy of two different language models. The "Pass budget" likely represents the computational resources allocated to the model during a verification or training process. The "Apollo" component appears to be an additional module or technique that boosts performance, particularly when computational resources are limited.
The diminishing returns observed with increasing pass budget and "Apollo" suggest that there's a trade-off between computational cost and accuracy gains. The initial steep increase in accuracy with "Apollo" indicates that it effectively leverages limited resources, while the plateau suggests that further investment in pass budget yields smaller improvements.
The difference in the overall accuracy levels between the Goedel and Kimina models suggests inherent differences in their architectures or training data. The Kimina model, even without Apollo, achieves higher accuracy than the Goedel model, indicating a potentially more robust or efficient base model. The charts provide valuable insights for optimizing resource allocation and model selection based on desired accuracy levels and computational constraints.