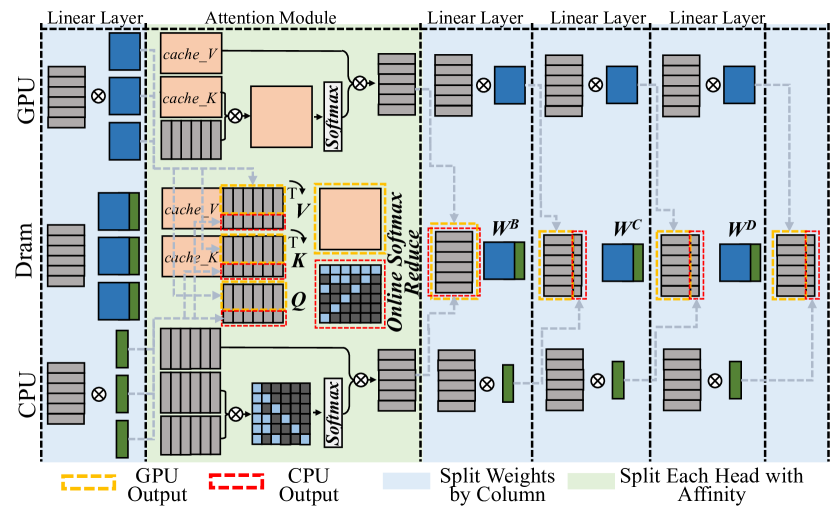
## Diagram: Hardware Acceleration of Attention Mechanism
### Overview
The image is a diagram illustrating the hardware acceleration of an attention mechanism, showing how computations are distributed across GPU, DRAM, and CPU. It details the flow of data through linear layers and an attention module, highlighting the splitting of weights and heads for parallel processing.
### Components/Axes
* **Title:** Hardware Acceleration of Attention Mechanism (inferred)
* **Vertical Labels (Left):** GPU, Dram, CPU
* **Horizontal Labels (Top):** Linear Layer, Attention Module, Linear Layer, Linear Layer, Linear Layer
* **Legend (Bottom):**
* Yellow Dashed Line: GPU Output
* Red Dashed Line: CPU Output
* Light Blue Fill: Split Weights by Column
* Light Green Fill: Split Each Head with Affinity
* **Attention Module Components:** cache\_V, cache\_K, V, K, Q, Online Softmax Reduce
* **Linear Layer Components:** W^B, W^C, W^D
### Detailed Analysis
The diagram is divided into vertical sections representing different stages of computation, and horizontal sections representing the hardware on which the computations are performed.
**GPU Section:**
* **Linear Layer 1 (Leftmost):** Input data (represented by stacked gray rectangles) is processed through a linear layer. The output is a blue rectangle.
* **Attention Module:**
* `cache_V` and `cache_K` (orange boxes) are inputs.
* The output of the attention module is a large orange rectangle after a Softmax operation.
* **Linear Layers 2-4:** The output from the attention module is processed through three subsequent linear layers. Each layer takes a blue rectangle as input and produces stacked gray rectangles as output.
**DRAM Section:**
* **Linear Layer 1:** Input data (stacked gray rectangles) is processed, resulting in a blue and green rectangle.
* **Attention Module:**
* `cache_V` and `cache_K` (orange boxes with red dashed borders) are inputs.
* V, K, and Q are computed.
* A matrix operation is performed, followed by "Online Softmax Reduce".
* **Linear Layers 2-4:** The output from the attention module is processed through three subsequent linear layers. Each layer takes a blue and green rectangle as input and produces stacked gray rectangles as output. The boxes containing W^B, W^C, and W^D have red dashed borders.
**CPU Section:**
* **Linear Layer 1:** Input data (stacked gray rectangles) is processed, resulting in a green rectangle.
* **Attention Module:**
* A matrix operation is performed, followed by a Softmax operation.
* **Linear Layers 2-4:** The output from the attention module is processed through three subsequent linear layers. Each layer takes a green rectangle as input and produces stacked gray rectangles as output.
**Data Flow:**
* Dashed gray lines indicate the flow of data between different hardware components and layers.
* Arrows indicate the direction of data flow.
### Key Observations
* The attention module is the most complex part of the diagram, involving multiple computations and data transformations.
* The GPU handles the initial and final linear layers, as well as part of the attention module.
* The DRAM handles intermediate computations within the attention module.
* The CPU handles the initial linear layer and part of the attention module.
* The splitting of weights and heads is indicated by the light blue and light green fills, respectively.
### Interpretation
The diagram illustrates a hardware-accelerated attention mechanism, where different parts of the computation are offloaded to different hardware components (GPU, DRAM, CPU) to improve performance. The attention module, being the most computationally intensive, is distributed across these components. The splitting of weights and heads further enables parallel processing, maximizing throughput. The use of GPU for initial and final linear layers suggests that these operations are well-suited for parallel processing on GPUs. The DRAM likely serves as a high-bandwidth memory for intermediate computations. The CPU handles specific parts of the computation, possibly those that are less amenable to parallelization or require more complex control logic. The diagram highlights the importance of hardware-software co-design for efficient implementation of attention mechanisms in deep learning models.