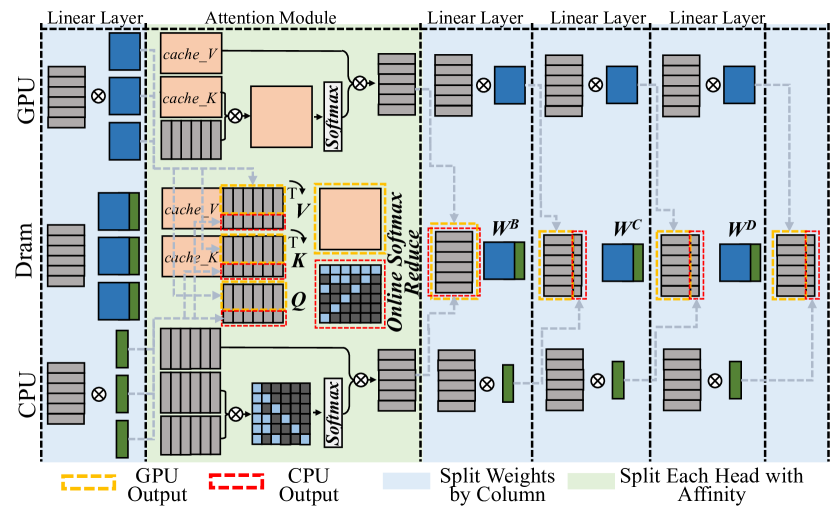
\n
## Diagram: System Architecture for Distributed Attention
### Overview
The image depicts a system architecture diagram for a distributed attention mechanism, likely within a machine learning model. The diagram illustrates the flow of data and computations across different processing units (GPU, DRAM, CPU) and through various layers (Linear, Attention). The diagram highlights data movement and processing steps, including matrix multiplications (denoted by the ⊗ symbol), attention calculations, and softmax operations.
### Components/Axes
The diagram is structured into three main vertical sections: GPU, DRAM, and CPU, positioned from left to right. Each section contains multiple blocks representing layers or operations. Key components and labels include:
* **GPU:** Contains "Linear Layer" and "Attention Module" blocks, with "cache\_V" and "cache\_K" within the Attention Module. "GPU Output" is indicated by a yellow dashed box.
* **Dram:** Contains "Linear Layer" blocks.
* **CPU:** Contains "Linear Layer" and "Attention Module" blocks, with "cache\_V" and "cache\_K" within the Attention Module. "CPU Output" is indicated by a red dashed box.
* **Attention Module:** Contains blocks labeled "V", "K", and "Q", with a "T" superscript on V and K. A "Softmax" operation is present.
* **Online Softmax Reduce:** A central block connecting the GPU and CPU attention modules.
* **Linear Layers:** Multiple "Linear Layer" blocks are present after the "Online Softmax Reduce" block.
* **Split Weights by Column:** A block indicating weight splitting.
* **Split Each Head with Affinity:** A block indicating head splitting.
* **Weight Matrices:** "WB", "WC", and "WD" are labeled within the "Split Each Head with Affinity" section.
* **Data Flow:** Arrows indicate the direction of data flow between blocks.
* **Matrix Multiplication:** The symbol "⊗" represents matrix multiplication.
### Detailed Analysis or Content Details
The diagram shows a parallel processing architecture.
1. **GPU Side:** The GPU processes data through a Linear Layer, then an Attention Module. The Attention Module utilizes "cache\_V" and "cache\_K" for storing values and keys. The output of the Attention Module is then passed through a Softmax function.
2. **CPU Side:** The CPU mirrors the GPU's processing flow with a Linear Layer and Attention Module, also utilizing "cache\_V" and "cache\_K" and a Softmax function.
3. **Attention Calculation:** The Attention Module calculates attention weights using Query (Q), Key (K), and Value (V) matrices. The transpose of K (K<sup>T</sup>) is used in the calculation.
4. **Online Softmax Reduce:** The outputs from the GPU and CPU Attention Modules are combined and processed by an "Online Softmax Reduce" operation.
5. **Subsequent Linear Layers:** The output of the "Online Softmax Reduce" is then passed through multiple Linear Layers.
6. **Weight Splitting:** The weights are split by column, and then each head is split with affinity. The resulting weights are labeled as "WB", "WC", and "WD".
7. **Output:** The final output is indicated by the "GPU Output" (yellow dashed box) and "CPU Output" (red dashed box).
### Key Observations
* The architecture employs a parallel processing strategy, utilizing both GPU and CPU for attention calculations.
* Caching mechanisms ("cache\_V", "cache\_K") are used within the Attention Modules on both the GPU and CPU.
* The "Online Softmax Reduce" operation suggests a distributed softmax calculation.
* Weight splitting and head splitting are employed to optimize the model's performance.
* The diagram does not provide specific numerical values or data points. It is a conceptual representation of the architecture.
### Interpretation
This diagram illustrates a distributed attention mechanism designed to leverage the computational resources of both GPUs and CPUs. The parallel processing approach aims to accelerate the attention calculation, which is a computationally intensive operation in many machine learning models, particularly in natural language processing. The use of caching suggests an attempt to reduce memory access latency and improve efficiency. The weight splitting and head splitting techniques are likely employed to reduce the model's memory footprint and improve scalability. The "Online Softmax Reduce" operation indicates a strategy for combining the attention weights calculated on the GPU and CPU in a distributed manner. The diagram suggests a sophisticated architecture optimized for performance and scalability in attention-based models. The diagram is a high-level overview and does not provide details on the specific implementation or optimization techniques used. It is a conceptual blueprint rather than a detailed specification.