TECHNICAL ASSET FINGERPRINT
78bdd42bc6e55a379a6ed763
Click to view fullscreen
Press ESC or click to close
FOUND IN PAPERS
EXPERT: healer-alpha-free VERSION 1
RUNTIME: free/openrouter/healer-alpha
INTEL_VERIFIED
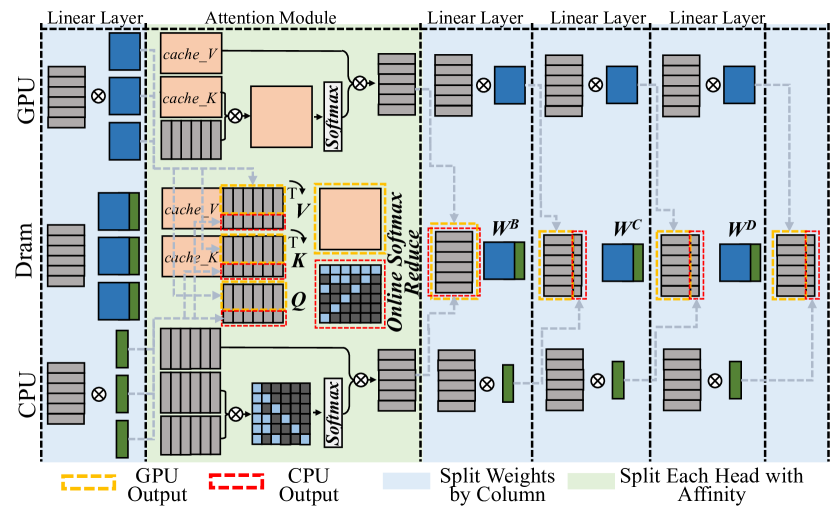
## System Architecture Diagram: Hybrid GPU-CPU Attention Mechanism with Memory Hierarchy
### Overview
This image is a technical system architecture diagram illustrating a hybrid computing pipeline for a neural network's attention mechanism. It details the data flow and computational partitioning between a GPU, DRAM (main memory), and a CPU. The diagram emphasizes how operations, weights, and outputs are split and managed across these hardware components to optimize performance, likely for large language model inference.
### Components/Axes
The diagram is organized into three primary horizontal layers (from top to bottom) and several vertical processing stages.
**Hardware Layers (Left Labels):**
* **GPU** (Top Layer)
* **Dram** (Middle Layer)
* **CPU** (Bottom Layer)
**Vertical Processing Stages (Top Labels):**
1. **Linear Layer** (First column)
2. **Attention Module** (Second, largest column, with a light green background)
3. **Linear Layer** (Third column)
4. **Linear Layer** (Fourth column)
5. **Linear Layer** (Fifth column)
**Legend (Bottom of Diagram):**
* **Yellow Dashed Box:** `GPU Output`
* **Red Dashed Box:** `CPU Output`
* **Light Blue Shading:** `Split Weights by Column`
* **Light Green Shading:** `Split Each Head with Affinity`
**Key Components & Labels within the Diagram:**
* **Linear Layer Blocks:** Represented by stacks of rectangles (blue for GPU, green for CPU, grey for DRAM) with a multiplication symbol (⊗) indicating a matrix operation.
* **Attention Module Components:**
* `cache_V` (Cached Values)
* `cache_K` (Cached Keys)
* `Q` (Query matrix)
* `V` (Value matrix)
* `K` (Key matrix)
* `Softmax` (Softmax operation block)
* `Online Softmax Reduce` (A specific, likely optimized, softmax computation block)
* **Weight Matrices (in Linear Layers after Attention):**
* `W^B`
* `W^C`
* `W^D`
* **Data Flow Indicators:** Solid and dashed arrows show the movement of data (tensors) between components. Dashed grey lines often indicate control or dependency flows.
### Detailed Analysis
The diagram depicts a sophisticated pipeline where computation is strategically divided:
1. **Initial Linear Layer:** The process begins with a linear layer whose weights and computations are split. The GPU handles a portion (blue blocks), the DRAM holds another portion (grey blocks), and the CPU handles a third (green blocks).
2. **Attention Module (Core Processing):**
* **GPU Path:** The GPU accesses its local `cache_V` and `cache_K`, performs a matrix multiplication (⊗), and feeds into a `Softmax` block.
* **DRAM/CPU Path:** This is the most complex path. The DRAM holds `cache_V`, `cache_K`, and the `Q` matrix. Data flows to the CPU, which performs a matrix multiplication. The results interact with an `Online Softmax Reduce` block (highlighted with a red dashed `CPU Output` box). The output of this softmax is then used in another matrix multiplication with the `V` and `K` matrices from DRAM.
* **Affinity-Based Splitting:** The light green shading over the entire Attention Module indicates that the multi-head attention mechanism is being split based on "affinity," meaning different attention heads or parts of heads are assigned to different hardware units (GPU vs. CPU) for parallel processing.
3. **Subsequent Linear Layers:** Following the attention module, there are three more linear layers. The diagram shows that the weight matrices (`W^B`, `W^C`, `W^D`) for these layers are "Split... by Column" (light blue shading). This means different columns of the weight matrices are assigned to different processing units. The outputs from these layers are a mix of `GPU Output` (yellow dashed) and `CPU Output` (red dashed).
4. **Data Movement:** The flow is not strictly top-down. There is significant data exchange between the GPU and DRAM layers, and between the DRAM and CPU layers, as indicated by the network of arrows. The CPU and GPU work in parallel on different parts of the same overall operation.
### Key Observations
* **Asymmetric Processing:** The GPU and CPU paths through the Attention Module are not identical. The CPU path includes the specialized `Online Softmax Reduce` step, suggesting a different, possibly more memory-efficient, algorithmic implementation for the CPU.
* **Fine-Grained Partitioning:** The system employs two distinct splitting strategies: splitting by column for linear layer weights and splitting by head affinity for the attention mechanism. This indicates a highly optimized design for heterogeneous hardware.
* **Central Role of DRAM:** DRAM acts as the central memory hub, holding shared data (`cache_V`, `cache_K`, `Q`, `V`, `K`) that both the GPU and CPU access and modify.
* **Output Fusion:** The final outputs of the pipeline are a combination of results computed on the GPU and the CPU, implying a synchronization or aggregation step at the end (not shown in this diagram).
### Interpretation
This diagram illustrates a **hardware-aware, hybrid execution engine for transformer models**. The core innovation is the intelligent partitioning of both the **computation** (attention heads, linear layer columns) and the **data** (cached keys/values, weight matrices) across a GPU and a CPU.
* **Purpose:** The goal is to overcome memory capacity and bandwidth limitations when running very large models. By splitting the workload, the system can leverage the GPU's high computational throughput for some parts while using the CPU and its larger accessible memory (DRAM) for other parts, effectively increasing the total usable memory and compute resources.
* **How Elements Relate:** The GPU and CPU are not working in a simple master-slave relationship but as parallel peers. The DRAM serves as the shared memory space that enables this collaboration. The "affinity" splitting suggests an intelligent scheduler that assigns attention heads to the processor best suited to handle them based on their memory footprint or computational needs.
* **Notable Design Choice:** The use of `Online Softmax Reduce` on the CPU path is significant. Standard softmax requires computing a global sum for normalization, which can be a memory bottleneck. An "online" or "reduced" version likely computes this in a more streaming, memory-efficient fashion, which is crucial when the CPU is managing data from large DRAM.
* **Implication:** This architecture enables the inference of models that are too large to fit entirely in GPU memory, by strategically offloading parts of the computation and data to the CPU and system memory, thereby balancing the load across the entire hardware system.
DECODING INTELLIGENCE...