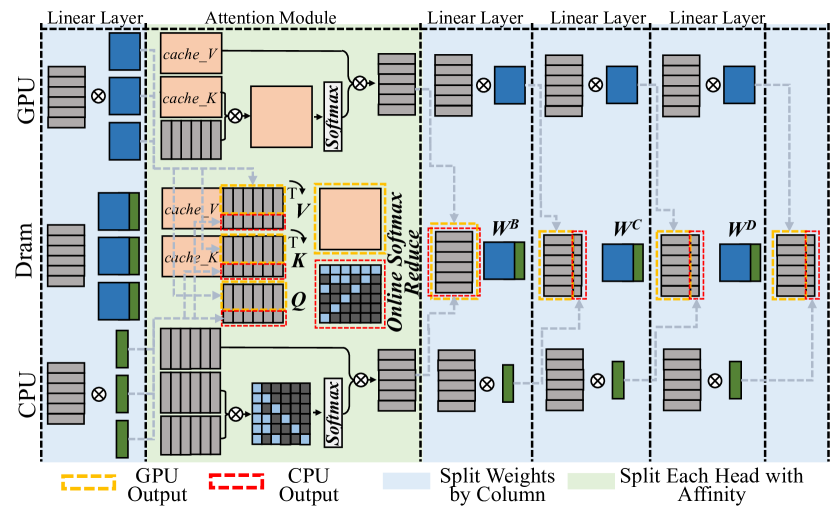
## Diagram: Neural Network Architecture with Hardware-Specific Computation Flow
### Overview
The diagram illustrates a hybrid neural network architecture that distributes computations across GPU, DRAM, and CPU. It emphasizes memory caching strategies, attention mechanisms, and parallel processing optimizations. The flow progresses from GPU → DRAM → CPU, with explicit hardware-specific operations and data transformations.
### Components/Axes
**Legend:**
- **Yellow dashed lines**: GPU Output
- **Red dashed lines**: CPU Output
- **Blue solid lines**: Split Weights by Column
- **Green solid lines**: Split Each Head with Affinity
**Key Elements:**
1. **GPU Section (Top):**
- Linear Layer (gray blocks)
- Attention Module (orange blocks):
- `cache_V` (blue)
- `cache_K` (blue)
- `Q`, `V`, `K` (black/white checkered)
- `Softmax` (orange)
- Outputs: GPU Output (yellow dashed)
2. **DRAM Section (Middle):**
- Caches: `cache_V`, `cache_K` (blue)
- Attention Operations:
- `Q`, `V`, `K` (black/white checkered)
- `Softmax` (orange)
- Outputs: GPU Output (yellow dashed) and CPU Output (red dashed)
3. **CPU Section (Bottom):**
- Linear Layers (gray blocks):
- `W_B`, `W_C`, `W_D` (blue)
- Splitting Strategies:
- Split Weights by Column (blue)
- Split Each Head with Affinity (green)
- Outputs: CPU Output (red dashed)
### Detailed Analysis
**GPU Operations:**
- Linear layers (gray) process inputs before attention module
- Attention module uses cached `V`/`K` (blue) and computes `Q`/`V`/`K` (black/white)
- `Softmax` (orange) applied to attention scores
- Outputs flow to DRAM via yellow dashed lines
**DRAM Operations:**
- Caches `V`/`K` (blue) enable efficient attention computation
- `Q` (black/white) interacts with cached `V`/`K`
- `Softmax` (orange) computes attention weights
- Dual outputs: GPU Output (yellow) and CPU Output (red)
**CPU Operations:**
- Linear layers (`W_B`, `W_C`, `W_D`) process attention outputs
- Weights split by column (blue) for parallel processing
- Heads split with affinity (green) for specialized processing
- Final outputs via red dashed lines
### Key Observations
1. **Hardware Specialization:**
- GPU handles attention module and initial linear layers
- CPU manages final linear transformations with specialized weight splitting
- DRAM acts as intermediate buffer for cached attention parameters
2. **Memory Optimization:**
- `cache_V`/`cache_K` (blue) reduce redundant computations
- Checkered `Q`/`V`/`K` blocks suggest dynamic computation paths
3. **Parallelism Strategies:**
- Column-wise weight splitting (blue) enables vectorized operations
- Affinity-based head splitting (green) optimizes CPU core utilization
4. **Flow Direction:**
- Data flows GPU → DRAM → CPU
- Attention module acts as computational bottleneck
- Multiple softmax operations indicate multi-stage processing
### Interpretation
This architecture demonstrates a multi-stage computation pipeline optimized for large-scale neural networks:
1. **GPU Acceleration:** The attention module (critical for transformer models) is offloaded to GPU for parallel matrix operations
2. **Memory Efficiency:** DRAM caching of `V`/`K` parameters reduces memory bandwidth requirements
3. **CPU Specialization:** Final linear layers use column-wise weight splitting and affinity-based head processing to maximize CPU core utilization
4. **Hybrid Workflow:** The system balances GPU parallelism with CPU specialization, suggesting a design for models requiring both attention mechanisms and complex post-processing
The diagram reveals a sophisticated approach to distributed computing where each hardware component handles specific computational phases, with DRAM serving as a critical intermediary for parameter caching and data transfer.