\n
## Diagram: Parallel Neural Network Processing
### Overview
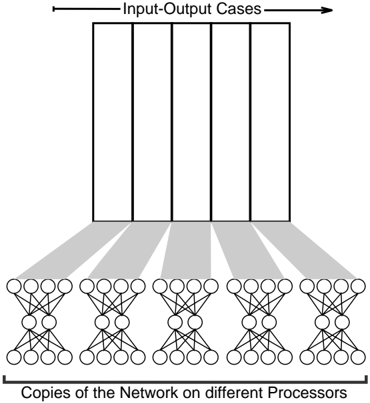
The image depicts a diagram illustrating a parallel processing architecture for a neural network. It shows multiple copies of a neural network operating on different processors, each processing a subset of input-output cases. The diagram highlights the distribution of workload across these processors.
### Components/Axes
The diagram consists of two main sections:
1. **Input-Output Cases:** A rectangular block at the top, divided into approximately 6 vertical sections, representing different input-output cases. An arrow indicates the direction of processing.
2. **Copies of the Network on different Processors:** A row of 6 identical neural network diagrams at the bottom. Each network consists of input nodes, hidden layers, and output nodes.
A label at the bottom reads: "Copies of the Network on different Processors".
A label at the top-right reads: "Input-Output Cases".
### Detailed Analysis or Content Details
The diagram shows a clear one-to-one mapping between the input-output cases and the copies of the neural network. Each neural network appears to have approximately 4 input nodes, 2 hidden layers with approximately 5 nodes each, and 1 output node.
The connections between the input-output cases and the neural networks are represented by gray shaded lines. Each input-output case is connected to each of the neural networks. This suggests that each processor is working on a different subset of the overall dataset.
There are no numerical values or specific data points present in the diagram. It is a conceptual illustration of a parallel processing scheme.
### Key Observations
The diagram emphasizes the parallel nature of the processing. The identical neural networks suggest that the same model is being used across all processors. The distribution of input-output cases implies a data parallelism approach, where the dataset is divided among the processors.
### Interpretation
This diagram illustrates a data-parallel approach to training or applying a neural network. By replicating the network across multiple processors, the workload can be distributed, potentially leading to faster processing times. The diagram suggests that the input data is partitioned and fed to each processor independently. This is a common strategy for scaling neural network computations, especially with large datasets. The lack of specific details about the network architecture or the data suggests that the diagram is intended to convey a general principle rather than a specific implementation. The diagram does not provide any information about how the results from the different processors are combined or synchronized. It is a high-level conceptual illustration.