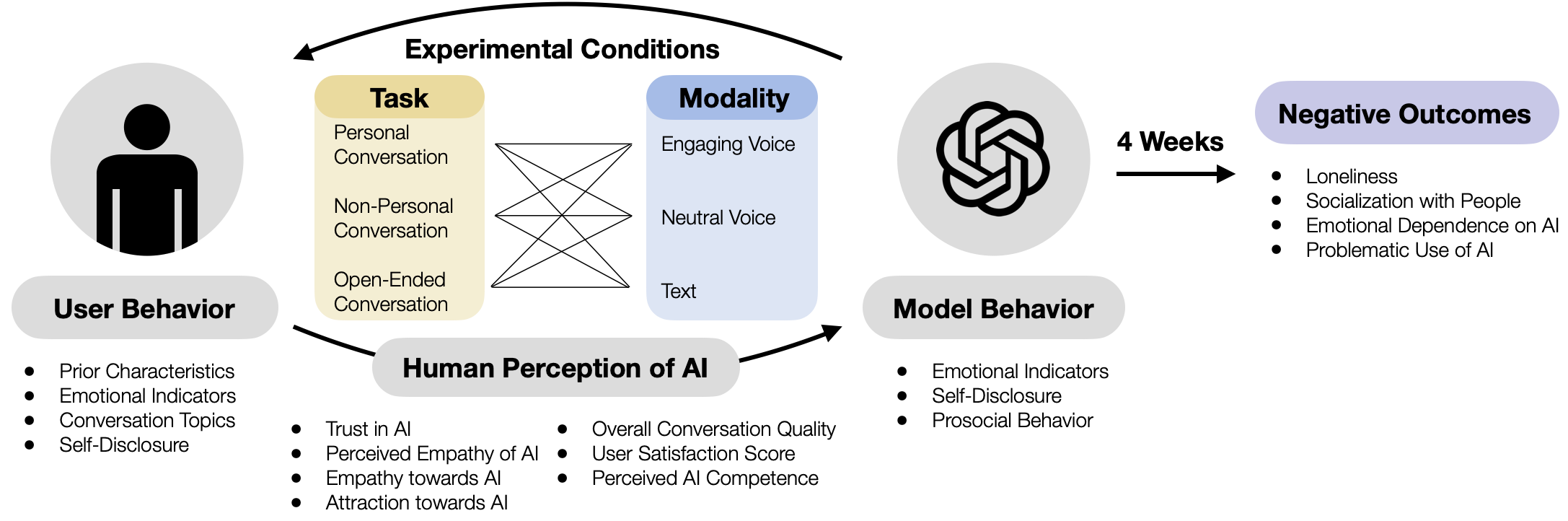
## Diagram: Experimental Framework for Human-AI Interaction Study
### Overview
This image is a conceptual diagram illustrating the structure and variables of a longitudinal experimental study on human interaction with an AI model. It maps the flow from user characteristics and experimental conditions, through human perception and model behavior, to potential negative outcomes over a 4-week period.
### Components/Axes
The diagram is organized into several interconnected components, primarily flowing from left to right.
**1. Left Section: User Behavior**
* **Icon:** A black silhouette of a person inside a light gray circle.
* **Label:** "User Behavior" in a gray rounded rectangle.
* **Listed Variables (Bullet Points):**
* Prior Characteristics
* Emotional Indicators
* Conversation Topics
* Self-Disclosure
**2. Center Section: Experimental Conditions & Human Perception**
* **Top Label:** "Experimental Conditions" with a curved arrow pointing from the user to this section.
* **Two Main Boxes:**
* **Task (Yellow Box):** Contains three conversation types:
* Personal Conversation
* Non-Personal Conversation
* Open-Ended Conversation
* **Modality (Light Blue Box):** Contains three interaction modes:
* Engaging Voice
* Neutral Voice
* Text
* **Connection:** A star-like web of lines connects each item in the "Task" box to each item in the "Modality" box, indicating a full factorial design (all combinations are tested).
* **Bottom Label:** "Human Perception of AI" in a gray rounded rectangle, with an arrow pointing from it to "Model Behavior".
* **Listed Variables (Two Columns of Bullet Points):**
* **Left Column:**
* Trust in AI
* Perceived Empathy of AI
* Empathy towards AI
* Attraction towards AI
* **Right Column:**
* Overall Conversation Quality
* User Satisfaction Score
* Perceived AI Competence
**3. Right-Center Section: Model Behavior**
* **Icon:** A black, stylized, interlocking knot symbol (resembling the OpenAI logo) inside a light gray circle.
* **Label:** "Model Behavior" in a gray rounded rectangle.
* **Listed Variables (Bullet Points):**
* Emotional Indicators
* Self-Disclosure
* Prosocial Behavior
**4. Right Section: Negative Outcomes**
* **Temporal Arrow:** A black arrow labeled "4 Weeks" points from the "Model Behavior" section to the "Negative Outcomes" section.
* **Label:** "Negative Outcomes" in a light purple rounded rectangle.
* **Listed Variables (Bullet Points):**
* Loneliness
* Socialization with People
* Emotional Dependence on AI
* Problematic Use of AI
### Detailed Analysis
The diagram defines a clear experimental pathway:
1. **Input:** A user with specific "Prior Characteristics" and "Emotional Indicators" engages in the experiment.
2. **Manipulation:** The experiment manipulates two independent variables: the **Task** (type of conversation) and the **Modality** (interface of the AI). The connecting lines show that every task type is paired with every modality.
3. **Mediating Variables:** The interaction influences the user's "Human Perception of AI" (e.g., trust, perceived empathy) and the observed "Model Behavior" (e.g., its emotional indicators, self-disclosure).
4. **Outcome:** After a period of **4 Weeks**, the study measures potential "Negative Outcomes" such as increased loneliness or problematic AI use.
### Key Observations
* The study is longitudinal, measuring outcomes over a 4-week period.
* It employs a full factorial design for the core experimental conditions (3 Tasks x 3 Modalities = 9 unique conditions).
* The diagram explicitly links user inputs, experimental manipulations, perceptual and behavioral mediators, and long-term psychological outcomes.
* The "Negative Outcomes" are framed as the dependent variables of primary interest for risk assessment.
### Interpretation
This diagram outlines a research framework designed to investigate the potential risks of prolonged, emotionally-engaging human-AI interaction. It hypothesizes that specific combinations of conversational tasks (especially personal ones) and modalities (especially engaging voice) will influence how users perceive the AI and how the AI behaves. These perceptions and behaviors are then posited to mediate the development of negative psychological outcomes over time.
The framework suggests a causal chain: **User Traits + Experimental Design → Perceptions & Behaviors → Long-term Risks**. The inclusion of "Socialization with People" under "Negative Outcomes" implies the study may measure a *decrease* in human socialization as a risk factor. The model is comprehensive, accounting for both the user's state and the AI's designed behavior as contributors to potential harm.