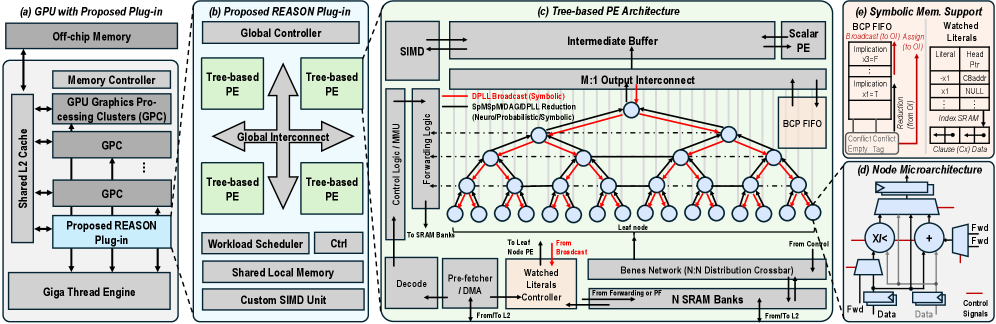
\n
## Diagram: REASON Architecture
### Overview
The image presents a detailed architectural diagram of the REASON system, a proposed plug-in for GPUs. It illustrates the integration of the REASON plug-in with existing GPU components and details the internal architecture of the REASON processing elements (PEs). The diagram is divided into four main sections: (a) GPU with Proposed Plug-in, (b) Proposed REASON Plug-in, (c) Tree-based PE Architecture, and (d) PE Microarchitecture. The diagram uses block diagrams and interconnect lines to represent the different components and their relationships.
### Components/Axes
The diagram does not contain axes in the traditional sense of a chart. Instead, it uses labeled blocks and interconnects to represent components. Key components and labels include:
* **Off-chip Memory**
* **Memory Controller**
* **GPUs Processing Clusters (GPC)**
* **Shared L2 Cache**
* **Proposed REASON Plug-in**
* **Giga Thread Engine**
* **Global Controller**
* **Tree-based PE**
* **Global Interconnect**
* **Workload Scheduler**
* **Shared Local Memory**
* **Custom SIMD Unit**
* **SIMD**
* **Intermediate Buffer**
* **M:1 Output Interconnect**
* **Scalar PE**
* **BCP FIFO**
* **Control Logic / MMU Forwarding Logic**
* **DPLL Broadcast (Symbolic)**
* **SpM/MD/ADD/PLL Reduction (Neural/Probabilistic/Symbolic)**
* **To SRAM Banks**
* **From Node PE**
* **Leaf Node**
* **From Broadcast**
* **Bones Network (N x N Distribution Crossbar)**
* **N SRAM Banks**
* **From Forwarding of Literals**
* **Watched Literals**
* **Pre-fetcher / DMA**
* **From/To L2**
* **Symbolic Mem. Support**
* **Implication**
* **Reduction (from Ctrl)**
* **Index SRAM**
* **Conflict/Conflict Empty Clause**
* **Ctrl**
* **Data**
* **Control Signals**
* **Fwd**
* **XOR Gate**
* **Adder**
### Detailed Analysis or Content Details
**(a) GPU with Proposed Plug-in:** This section shows the REASON plug-in integrated into a standard GPU architecture. The plug-in connects to the GPU's shared L2 cache and is powered by the Giga Thread Engine and Custom SIMD Unit. The GPU also includes GPUs Processing Clusters (GPC) and a Memory Controller connected to Off-chip Memory.
**(b) Proposed REASON Plug-in:** This section details the internal components of the REASON plug-in. It includes a Global Controller, multiple Tree-based PEs connected via a Global Interconnect, a Workload Scheduler, and Shared Local Memory.
**(c) Tree-based PE Architecture:** This section illustrates the architecture of a single Tree-based PE. It features a SIMD unit, an Intermediate Buffer, and an M:1 Output Interconnect. The PE is composed of multiple nodes connected in a tree-like structure. Data flows from the bottom (SRAM Banks) up to the top (Scalar PE) through the tree. The diagram shows data paths for DPLL Broadcast (Symbolic) and SpM/MD/ADD/PLL Reduction (Neural/Probabilistic/Symbolic). Red lines indicate data flow, while blue lines represent control signals.
**(d) PE Microarchitecture:** This section provides a detailed view of the microarchitecture of a PE node. It includes an XOR gate, an adder, and control signals for data forwarding (Fwd).
### Key Observations
* The REASON plug-in appears to augment existing GPU capabilities with specialized processing elements for symbolic computation and neural/probabilistic reasoning.
* The tree-based PE architecture suggests a hierarchical processing approach, potentially enabling efficient parallelization.
* The inclusion of BCP FIFO and SRAM banks indicates a focus on memory access and data management.
* The diagram highlights the integration of symbolic and neural/probabilistic processing within the same architecture.
* The use of a Bones Network (N x N Distribution Crossbar) suggests a flexible and scalable interconnect for data distribution.
### Interpretation
The diagram demonstrates a novel architecture for integrating symbolic reasoning capabilities into a GPU. The REASON plug-in leverages a tree-based PE architecture to perform specialized computations, potentially accelerating tasks that are challenging for traditional GPUs. The combination of symbolic, neural, and probabilistic processing within the same system suggests a hybrid approach to AI, aiming to combine the strengths of different paradigms. The detailed microarchitecture of the PE nodes indicates a focus on efficient data manipulation and control. The overall design suggests a system optimized for complex reasoning tasks, potentially applicable to areas such as constraint solving, machine learning, and knowledge representation. The diagram is a high-level architectural overview and does not provide specific performance metrics or implementation details. However, it clearly outlines the key components and their relationships, providing a solid foundation for further investigation and development.