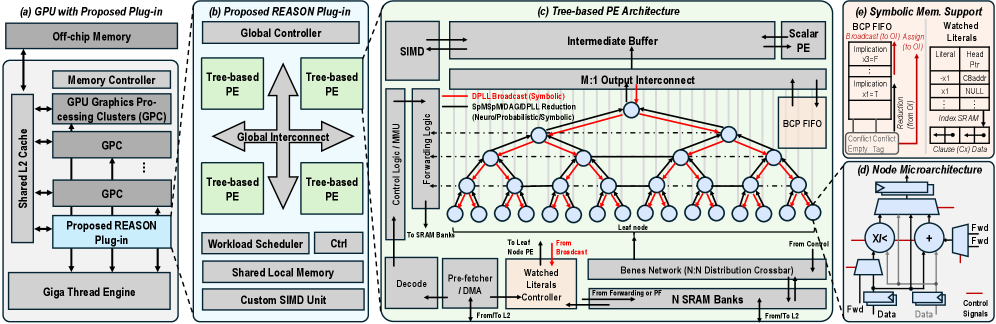
## Diagram: GPU Architecture with Proposed REASON Plug-in and Tree-based Processing Elements
### Overview
The diagram illustrates a multi-component GPU architecture with a proposed REASON plug-in, tree-based processing elements (PEs), symbolic memory support, and microarchitecture details. It emphasizes hierarchical data flow, parallel processing, and specialized memory management.
---
### Components/Axes
#### (a) GPU with Proposed Plug-in
- **Components**:
- Off-chip Memory → Memory Controller → GPU Graphics Processing Clusters (GPC) → Shared L2 Cache → Proposed REASON Plug-in → Giga Thread Engine.
- **Flow**: Data moves from off-chip memory through GPCs to the REASON plug-in, which interfaces with the Giga Thread Engine.
#### (b) Proposed REASON Plug-in
- **Components**:
- Global Controller → Tree-based PEs (4 instances) → Global Interconnect → Workload Scheduler → Shared Local Memory → Custom SIMD Unit.
- **Flow**: The Global Controller orchestrates Tree-based PEs via Global Interconnect, with workload scheduling and local memory management.
#### (c) Tree-based PE Architecture
- **Components**:
- SIMD → Intermediate Buffer → Scalar PE → M:1 Output Interconnect → BCP FIFO → DPLL Broadcast → SpMpMDAGIDPLL Reduction → Control Logic → Forwarding Logic → SRAM Banks → Decode → Pre-fetcher/DMA → Watched Literals → Leaf Nodes → Bennes Network → N:1 Distribution Crossbar → N SRAM Banks.
- **Flow**: Data flows from SIMD through scalar PEs, hierarchical interconnects, and memory banks, with symbolic operations (e.g., DPLL Broadcast) and conflict resolution.
#### (d) Node Microarchitecture
- **Components**:
- Forwarding Control → Fwd Data → Fwd Signals → Control Signals → Data.
- **Flow**: Internal node operations manage data and control signals for parallel execution.
#### (e) Symbolic Memory Support
- **Components**:
- BCP FIFO → BCP FIFO Broadcast → Implication → Reduction → Conflict → Empty Tag → Watched Literals.
- **Flow**: Symbolic operations (e.g., implication, reduction) are managed via BCP FIFO, with conflict resolution and literal tracking.
---
### Detailed Analysis
#### (a) GPU Architecture
- **Key Connections**:
- Shared L2 Cache is directly connected to GPCs, enabling low-latency data sharing.
- The Proposed REASON Plug-in acts as a bridge between GPCs and the Giga Thread Engine, suggesting specialized processing capabilities.
#### (b) REASON Plug-in
- **Global Interconnect**: Links all Tree-based PEs, enabling synchronized operations.
- **Workload Scheduler**: Manages task distribution to PEs, optimizing parallelism.
- **Custom SIMD Unit**: Likely accelerates specific instructions (e.g., vectorized operations).
#### (c) Tree-based PE Architecture
- **Hierarchical Structure**:
- Scalar PEs feed into M:1 Output Interconnect, reducing parallelism for efficient output handling.
- BCP FIFO manages symbolic data (e.g., implications, reductions) with conflict resolution (Conflict/Empty Tag).
- **Watched Literals**: Tracked via Pre-fetcher/DMA, indicating dynamic memory access patterns.
- **Bennes Network**: Distributes data across N SRAM Banks, suggesting N-way parallelism.
#### (d) Node Microarchitecture
- **Signal Flow**:
- Fwd Data and Fwd Signals propagate through Control Signals, enabling real-time adjustments.
- Data is processed locally before being routed to SRAM Banks.
#### (e) Symbolic Memory Support
- **BCP FIFO Operations**:
- Implication (x3-F, x1-T) and Reduction (x3-T, x1-NULL) operations are prioritized.
- Conflict resolution flags (Conflict/Empty Tag) ensure data integrity.
- Watched Literals are indexed via SRAM, with clauses (Cx) and data (Dx) stored separately.
---
### Key Observations
1. **Hierarchical Parallelism**: Tree-based PEs and M:1 Output Interconnect suggest a focus on scalable parallelism with controlled data aggregation.
2. **Symbolic Data Handling**: BCP FIFO and conflict resolution mechanisms indicate support for complex, logic-based operations (e.g., probabilistic or neuro-symbolic computing).
3. **Memory Optimization**: Shared Local Memory and N SRAM Banks reduce off-chip memory access, improving latency.
4. **REASON Plug-in Integration**: The plug-in bridges traditional GPU components (GPCs) with advanced processing units (Tree-based PEs), enabling hybrid workloads.
---
### Interpretation
- **Purpose**: The architecture targets applications requiring parallel symbolic computation (e.g., AI, cryptography) by combining GPU efficiency with specialized processing elements.
- **Innovations**:
- The REASON Plug-in introduces a novel layer for managing tree-based PEs, decoupling them from traditional GPU workflows.
- Symbolic Memory Support (BCP FIFO) addresses challenges in handling logic-heavy data, critical for neuro-symbolic systems.
- **Trade-offs**:
- Complexity in control logic (e.g., Forwarding Logic, Conflict Resolution) may increase design overhead.
- Hierarchical interconnects (Global Interconnect, Bennes Network) could introduce latency if not optimized.
- **Outliers**: The Custom SIMD Unit’s role is unclear without context, but its placement suggests it handles low-level, repetitive tasks to offload PEs.
This architecture represents a shift toward domain-specific acceleration, blending GPU generality with PE specialization for emerging computational paradigms.