## Bar Chart: Comparison of LLMs Across Datasets
### Overview
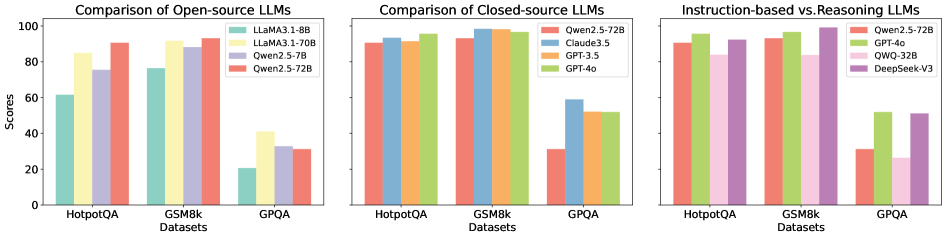
The image is a grouped bar chart comparing the performance of various Large Language Models (LLMs) across three datasets: **HotpotQA**, **GSM8k**, and **GPQA**. The chart is divided into three sections:
1. **Open-source LLMs**
2. **Closed-source LLMs**
3. **Instruction-based vs. Reasoning LLMs**
Each section uses distinct color-coded models, with scores normalized to a 0–100 scale.
---
### Components/Axes
- **X-axis (Datasets)**:
- HotpotQA
- GSM8k
- GPQA
- **Y-axis (Scores)**:
- Scale: 0 to 100 (discrete increments of 20).
- **Legends**:
- **Open-source LLMs**:
- LLaMA3.1-8B (teal)
- LLaMA3.1-70B (yellow)
- Qwen2.5-72B (red)
- **Closed-source LLMs**:
- Qwen2.5-72B (red)
- Claude3.5 (blue)
- GPT-3.5 (orange)
- GPT-4o (green)
- **Instruction-based vs. Reasoning LLMs**:
- Qwen2.5-72B (red)
- GPT-4o (green)
- QWQ-32B (pink)
- DeepSeek-V3 (purple)
---
### Detailed Analysis
#### Open-source LLMs
- **HotpotQA**:
- LLaMA3.1-8B: ~60
- LLaMA3.1-70B: ~85
- Qwen2.5-72B: ~90
- **GSM8k**:
- LLaMA3.1-8B: ~75
- LLaMA3.1-70B: ~88
- Qwen2.5-72B: ~92
- **GPQA**:
- LLaMA3.1-8B: ~20
- LLaMA3.1-70B: ~40
- Qwen2.5-72B: ~30
#### Closed-source LLMs
- **HotpotQA**:
- Qwen2.5-72B: ~90
- Claude3.5: ~92
- GPT-3.5: ~91
- GPT-4o: ~95
- **GSM8k**:
- Qwen2.5-72B: ~93
- Claude3.5: ~95
- GPT-3.5: ~94
- GPT-4o: ~97
- **GPQA**:
- Qwen2.5-72B: ~30
- Claude3.5: ~58
- GPT-3.5: ~52
- GPT-4o: ~53
#### Instruction-based vs. Reasoning LLMs
- **HotpotQA**:
- Qwen2.5-72B: ~90
- GPT-4o: ~95
- QWQ-32B: ~85
- DeepSeek-V3: ~98
- **GSM8k**:
- Qwen2.5-72B: ~93
- GPT-4o: ~97
- QWQ-32B: ~88
- DeepSeek-V3: ~100
- **GPQA**:
- Qwen2.5-72B: ~30
- GPT-4o: ~52
- QWQ-32B: ~25
- DeepSeek-V3: ~50
---
### Key Observations
1. **Open-source LLMs**:
- Qwen2.5-72B consistently outperforms LLaMA variants across all datasets.
- LLaMA3.1-8B struggles significantly in GPQA (~20), while LLaMA3.1-70B improves but still lags behind Qwen2.5-72B.
2. **Closed-source LLMs**:
- GPT-4o dominates in all datasets, achieving the highest scores (e.g., ~97 in GSM8k).
- Claude3.5 and GPT-3.5 show similar performance, with Claude3.5 slightly ahead in HotpotQA.
3. **Instruction-based vs. Reasoning LLMs**:
- **Instruction-based models** (Qwen2.5-72B, GPT-4o) excel in **GSM8k** (reasoning-heavy dataset), with scores near 100.
- **Reasoning-based models** (DeepSeek-V3) underperform in GPQA (~50) but dominate in HotpotQA (~98).
- QWQ-32B (instruction-based) has the lowest scores in GPQA (~25).
---
### Interpretation
- **Model Type Impact**:
- Closed-source models (e.g., GPT-4o) generally outperform open-source models, suggesting proprietary architectures or training data advantages.
- Instruction-based models (e.g., Qwen2.5-72B) excel in reasoning tasks (GSM8k) but struggle with open-source benchmarks like GPQA.
- **Dataset-Specific Trends**:
- **GSM8k** (reasoning): Instruction-based models (Qwen2.5-72B, GPT-4o) achieve near-perfect scores (~93–97).
- **GPQA** (general knowledge): Open-source models (LLaMA3.1-8B) perform poorly (~20), while closed-source models (GPT-4o) achieve moderate scores (~53).
- **Anomalies**:
- DeepSeek-V3 (reasoning-based) achieves the highest score in GSM8k (~100) but underperforms in GPQA (~50), indicating specialization in reasoning tasks.
- QWQ-32B (instruction-based) has the lowest GPQA score (~25), suggesting limitations in general knowledge tasks.
- **Implications**:
- Closed-source models may offer better reliability for high-stakes applications.
- Instruction-based models are optimized for structured reasoning but lack versatility in open-ended tasks.
---
### Spatial Grounding & Trend Verification
- **Legend Placement**:
- Open-source legend: Top-left of the first section.
- Closed-source legend: Top-left of the second section.
- Instruction-based vs. Reasoning legend: Top-left of the third section.
- **Color Consistency**:
- Red consistently represents Qwen2.5-72B across all sections.
- Green represents GPT-4o in closed-source and instruction-based sections.
- **Trend Validation**:
- In Open-source LLMs, Qwen2.5-72B (red) slopes upward across datasets, confirming its dominance.
- In Closed-source LLMs, GPT-4o (green) shows a flat, high-performance trend.
---
### Content Details
- **Textual Elements**:
- No non-English text detected.
- Dataset labels and model names are explicitly annotated in legends.
- **Data Table Reconstruction**:
| Dataset | Model | Score |
|-------------|---------------------|-------|
| HotpotQA | LLaMA3.1-8B | ~60 |
| HotpotQA | LLaMA3.1-70B | ~85 |
| HotpotQA | Qwen2.5-72B | ~90 |
| GSM8k | LLaMA3.1-8B | ~75 |
| GSM8k | LLaMA3.1-70B | ~88 |
| GSM8k | Qwen2.5-72B | ~92 |
| GPQA | LLaMA3.1-8B | ~20 |
| GPQA | LLaMA3.1-70B | ~40 |
| GPQA | Qwen2.5-72B | ~30 |
| ... (repeated for closed-source and instruction-based sections) |
---
### Final Notes
The chart highlights trade-offs between model openness, architecture, and task specificity. While closed-source models dominate in general performance, open-source models like Qwen2.5-72B show promise in specialized domains. Further analysis could explore training data size, computational resources, or fine-tuning strategies to explain these disparities.