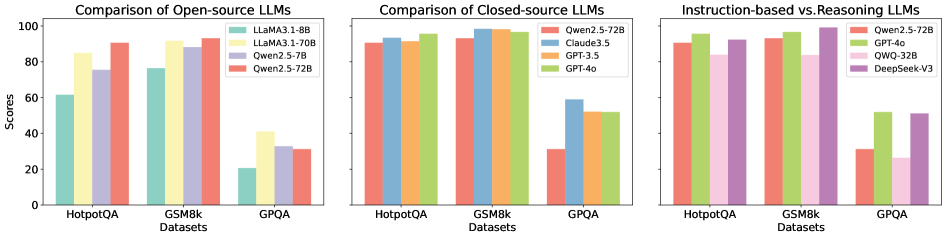
## Bar Chart: LLM Performance Comparison
### Overview
The image presents a comparative analysis of Large Language Models (LLMs) across three datasets: HotpotQA, GSM8k, and GPQA. The comparison is segmented into three charts: Open-source LLMs, Closed-source LLMs, and a comparison of Instruction-based vs. Reasoning LLMs. The y-axis represents "Scores" ranging from 0 to 100, while the x-axis represents the datasets. Each chart uses grouped bar graphs to display the performance of different LLMs on each dataset.
### Components/Axes
* **Y-axis:** "Scores" (Scale: 0 to 100, increments of 20)
* **X-axis:** "Datasets" (Categories: HotpotQA, GSM8k, GPQA)
* **Chart 1 (Open-source LLMs):**
* Legend:
* LLaMA3-1-8B (Light Blue)
* LLaMA3-1-70B (Pale Green)
* Qwen2-7B (Light Orange)
* Qwen2-5-72B (Light Red)
* **Chart 2 (Closed-source LLMs):**
* Legend:
* Qwen2.5-72B (Light Blue)
* Claude3.5 (Pale Green)
* GPT-3.5 (Light Orange)
* GPT-4o (Light Red)
* **Chart 3 (Instruction-based vs. Reasoning LLMs):**
* Legend:
* Qwen2.5-72B (Light Blue)
* GPT-4o (Pale Green)
* QWO-32B (Light Orange)
* DeepSeek-V3 (Light Red)
### Detailed Analysis
**Chart 1: Comparison of Open-source LLMs**
* **HotpotQA:**
* LLaMA3-1-8B: Approximately 62
* LLaMA3-1-70B: Approximately 86
* Qwen2-7B: Approximately 82
* Qwen2-5-72B: Approximately 88
* **GSM8k:**
* LLaMA3-1-8B: Approximately 78
* LLaMA3-1-70B: Approximately 92
* Qwen2-7B: Approximately 88
* Qwen2-5-72B: Approximately 90
* **GPQA:**
* LLaMA3-1-8B: Approximately 22
* LLaMA3-1-70B: Approximately 32
* Qwen2-7B: Approximately 28
* Qwen2-5-72B: Approximately 30
**Chart 2: Comparison of Closed-source LLMs**
* **HotpotQA:**
* Qwen2.5-72B: Approximately 92
* Claude3.5: Approximately 94
* GPT-3.5: Approximately 90
* GPT-4o: Approximately 96
* **GSM8k:**
* Qwen2.5-72B: Approximately 94
* Claude3.5: Approximately 96
* GPT-3.5: Approximately 92
* GPT-4o: Approximately 98
* **GPQA:**
* Qwen2.5-72B: Approximately 30
* Claude3.5: Approximately 34
* GPT-3.5: Approximately 28
* GPT-4o: Approximately 36
**Chart 3: Instruction-based vs. Reasoning LLMs**
* **HotpotQA:**
* Qwen2.5-72B: Approximately 92
* GPT-4o: Approximately 96
* QWO-32B: Approximately 88
* DeepSeek-V3: Approximately 86
* **GSM8k:**
* Qwen2.5-72B: Approximately 94
* GPT-4o: Approximately 98
* QWO-32B: Approximately 92
* DeepSeek-V3: Approximately 90
* **GPQA:**
* Qwen2.5-72B: Approximately 30
* GPT-4o: Approximately 36
* QWO-32B: Approximately 26
* DeepSeek-V3: Approximately 28
### Key Observations
* GPT-4o consistently achieves the highest scores across all datasets in the Closed-source and Instruction-based vs. Reasoning LLMs charts.
* LLaMA3-1-70B and Qwen2-5-72B generally outperform LLaMA3-1-8B and Qwen2-7B in the Open-source LLMs chart.
* Performance on GPQA is significantly lower than on HotpotQA and GSM8k for all models.
* The gap in performance between open-source and closed-source models is noticeable, with closed-source models generally achieving higher scores.
### Interpretation
The data suggests that GPT-4o is currently the leading LLM in terms of performance on these datasets. The larger models (e.g., LLaMA3-1-70B, Qwen2-5-72B) consistently outperform their smaller counterparts within the open-source category. The lower scores on GPQA indicate that this dataset presents a greater challenge for all models, potentially due to its specific characteristics or complexity. The consistent outperformance of closed-source models highlights the advantages of larger training datasets and more sophisticated architectures, which are often proprietary. The comparison between instruction-based and reasoning LLMs demonstrates that both types of models can achieve high performance, but GPT-4o still leads in this category. The data provides valuable insights for researchers and developers working on LLMs, indicating areas for improvement and potential directions for future research. The consistent trends across datasets suggest that the observed performance differences are not random and reflect genuine capabilities of the models.