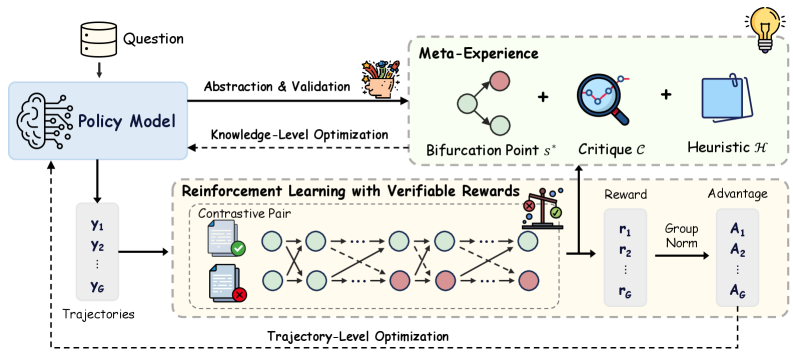
## Diagram: Reinforcement Learning with Verifiable Rewards
### Overview
The image is a diagram illustrating a reinforcement learning framework with verifiable rewards. It shows the flow of information and processes involved in training a policy model using meta-experience and reinforcement learning with verifiable rewards. The diagram includes components such as a policy model, meta-experience, reinforcement learning with verifiable rewards, trajectories, rewards, and advantages. The diagram also shows the optimization processes at both knowledge and trajectory levels.
### Components/Axes
* **Question:** Located at the top-left, represents the initial query or task.
* **Policy Model:** A neural network-like structure that takes a question as input and outputs trajectories.
* **Trajectories:** Represented as Y1, Y2, ..., YG, these are the sequences of actions generated by the policy model.
* **Meta-Experience:** Located at the top-right, it consists of:
* **Bifurcation Point s\***: A branching point in the decision-making process.
* **Critique C:** A mechanism for evaluating the quality of the trajectories.
* **Heuristic H:** A rule or guideline used to improve the policy.
* **Reinforcement Learning with Verifiable Rewards:** Located at the bottom-center, it includes:
* **Contrastive Pair:** A pair of trajectories, one successful (green checkmark) and one unsuccessful (red "X").
* A sequence of interconnected circles, some green and some red, representing the states in the trajectories.
* **Reward:** r1, r2, ..., rG, representing the rewards associated with each trajectory.
* **Group Norm:** A normalization process applied to the rewards.
* **Advantage:** A1, A2, ..., AG, representing the advantage function for each trajectory.
* **Abstraction & Validation:** A process that transforms the question into a suitable format for the policy model and validates the model's output.
* **Knowledge-Level Optimization:** A feedback loop that uses meta-experience to improve the policy model.
* **Trajectory-Level Optimization:** A feedback loop that uses reinforcement learning with verifiable rewards to improve the policy model.
### Detailed Analysis or Content Details
* **Flow of Information:**
* A "Question" is fed into the "Policy Model".
* The "Policy Model" generates "Trajectories" (Y1, Y2, ..., YG).
* The "Trajectories" are used in "Reinforcement Learning with Verifiable Rewards".
* "Meta-Experience" is used for "Knowledge-Level Optimization" of the "Policy Model".
* "Reinforcement Learning with Verifiable Rewards" is used for "Trajectory-Level Optimization" of the "Policy Model".
* **Contrastive Pair Details:**
* The contrastive pair consists of two documents. The top document has a green checkmark, indicating a positive example. The bottom document has a red "X", indicating a negative example.
* The sequence of circles represents the states in the trajectories. Green circles represent successful states, while red circles represent unsuccessful states. The connections between the circles represent the transitions between states.
* **Reward and Advantage:**
* The rewards (r1, r2, ..., rG) are normalized using a "Group Norm" function.
* The normalized rewards are used to calculate the advantages (A1, A2, ..., AG).
### Key Observations
* The diagram illustrates a closed-loop system where the policy model is continuously improved using both meta-experience and reinforcement learning with verifiable rewards.
* The use of contrastive pairs in reinforcement learning helps to guide the policy model towards generating successful trajectories.
* The knowledge-level and trajectory-level optimization processes work together to improve the overall performance of the policy model.
### Interpretation
The diagram presents a sophisticated approach to reinforcement learning that incorporates meta-experience and verifiable rewards. This framework aims to improve the efficiency and effectiveness of policy learning by leveraging prior knowledge and providing clear signals for successful and unsuccessful trajectories. The use of contrastive pairs is a key element, as it allows the model to learn from both positive and negative examples, leading to more robust and reliable policies. The combination of knowledge-level and trajectory-level optimization ensures that the policy model is continuously refined at both high and low levels of abstraction. The diagram suggests a system designed for complex tasks where learning from experience and leveraging prior knowledge are crucial for success.