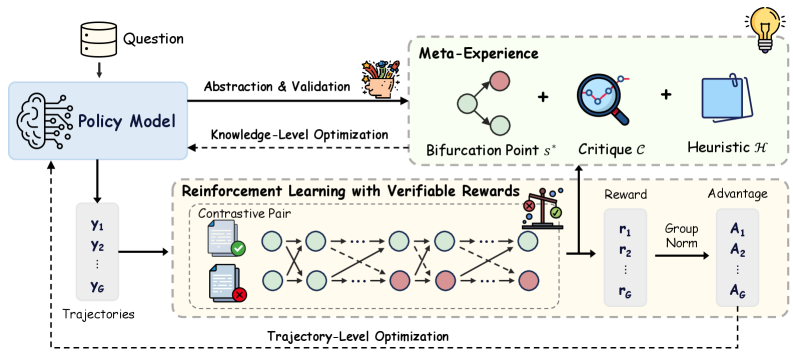
\n
## Diagram: Meta-Experience Enhanced Reinforcement Learning
### Overview
The image depicts a diagram illustrating a system for reinforcement learning enhanced with a "Meta-Experience" component. The system takes a "Question" as input, processes it through a "Policy Model," and utilizes reinforcement learning with verifiable rewards, guided by meta-experience derived from abstraction, validation, critique, and heuristics. The diagram highlights the flow of information and the interaction between different modules.
### Components/Axes
The diagram is structured into several key components:
* **Question Input:** A cylindrical shape labeled "Question" at the top-left.
* **Policy Model:** A brain-shaped icon connected to the "Question" input, labeled "Policy Model."
* **Meta-Experience:** A section at the top-right containing:
* A flower pot labeled "Abstraction & Validation."
* A network of nodes labeled "Bifurcation Point s*."
* A magnifying glass labeled "Critique C."
* A folder labeled "Heuristic H."
* A lightbulb icon.
* **Reinforcement Learning with Verifiable Rewards:** A large rectangular section in the center containing:
* "Contrastive Pair" represented by two document icons, one with a green checkmark and one with a red cross.
* A network of nodes connected by arrows, representing state transitions.
* A scale icon representing "Reward."
* A column labeled "r<sub>1</sub>" through "r<sub>g</sub>" representing rewards.
* A "Group Norm" block.
* A column labeled "A<sub>1</sub>" through "A<sub>g</sub>" representing advantages.
* **Trajectories:** A vertical stack of rectangles labeled "Y<sub>1</sub>" through "Y<sub>g</sub>" on the left side, representing trajectories.
* **Labels:** "Knowledge-Level Optimization", "Trajectory-Level Optimization".
### Detailed Analysis or Content Details
The diagram illustrates the following flow:
1. A "Question" is fed into the "Policy Model."
2. The "Policy Model" generates "Trajectories" (Y<sub>1</sub> to Y<sub>g</sub>).
3. These trajectories are used in "Reinforcement Learning with Verifiable Rewards."
4. The reinforcement learning process involves a "Contrastive Pair" of states (one positive, one negative).
5. State transitions are represented by nodes connected by arrows. The arrows indicate the flow of the reinforcement learning process.
6. Rewards (r<sub>1</sub> to r<sub>g</sub>) are calculated and normalized using "Group Norm."
7. Advantages (A<sub>1</sub> to A<sub>g</sub>) are computed based on the rewards.
8. The "Meta-Experience" component provides feedback to the reinforcement learning process through "Abstraction & Validation," "Critique C," and "Heuristic H," influencing the "Bifurcation Point s*."
9. "Knowledge-Level Optimization" connects the Policy Model to the Meta-Experience.
10. "Trajectory-Level Optimization" connects the Reinforcement Learning section to the Trajectories.
The number of trajectories, rewards, and advantages is denoted by "g," suggesting a variable number of elements. The diagram does not provide specific numerical values for rewards or advantages.
### Key Observations
* The diagram emphasizes the integration of meta-experience into the reinforcement learning loop.
* The contrastive learning aspect is highlighted by the positive/negative state pair.
* The use of "Group Norm" suggests a normalization technique is applied to the rewards.
* The diagram is conceptual and does not provide quantitative data.
### Interpretation
The diagram illustrates a sophisticated reinforcement learning framework that incorporates meta-experience to improve learning efficiency and robustness. The "Meta-Experience" component acts as a higher-level reasoning layer, providing guidance and feedback to the reinforcement learning agent. The "Abstraction & Validation" step likely involves summarizing and verifying the learned knowledge, while "Critique C" and "Heuristic H" provide corrective feedback and domain-specific knowledge. The "Bifurcation Point s*" suggests a decision-making process where the agent chooses between different actions based on the meta-experience. The contrastive learning approach, using positive and negative examples, helps the agent to distinguish between desirable and undesirable states. The overall system aims to achieve "Knowledge-Level Optimization" and "Trajectory-Level Optimization," leading to more effective and reliable reinforcement learning. The diagram suggests a system designed for complex tasks where explicit rewards are difficult to define, and meta-knowledge is crucial for guiding the learning process. The lightbulb icon suggests the system is designed to generate new insights or solutions.