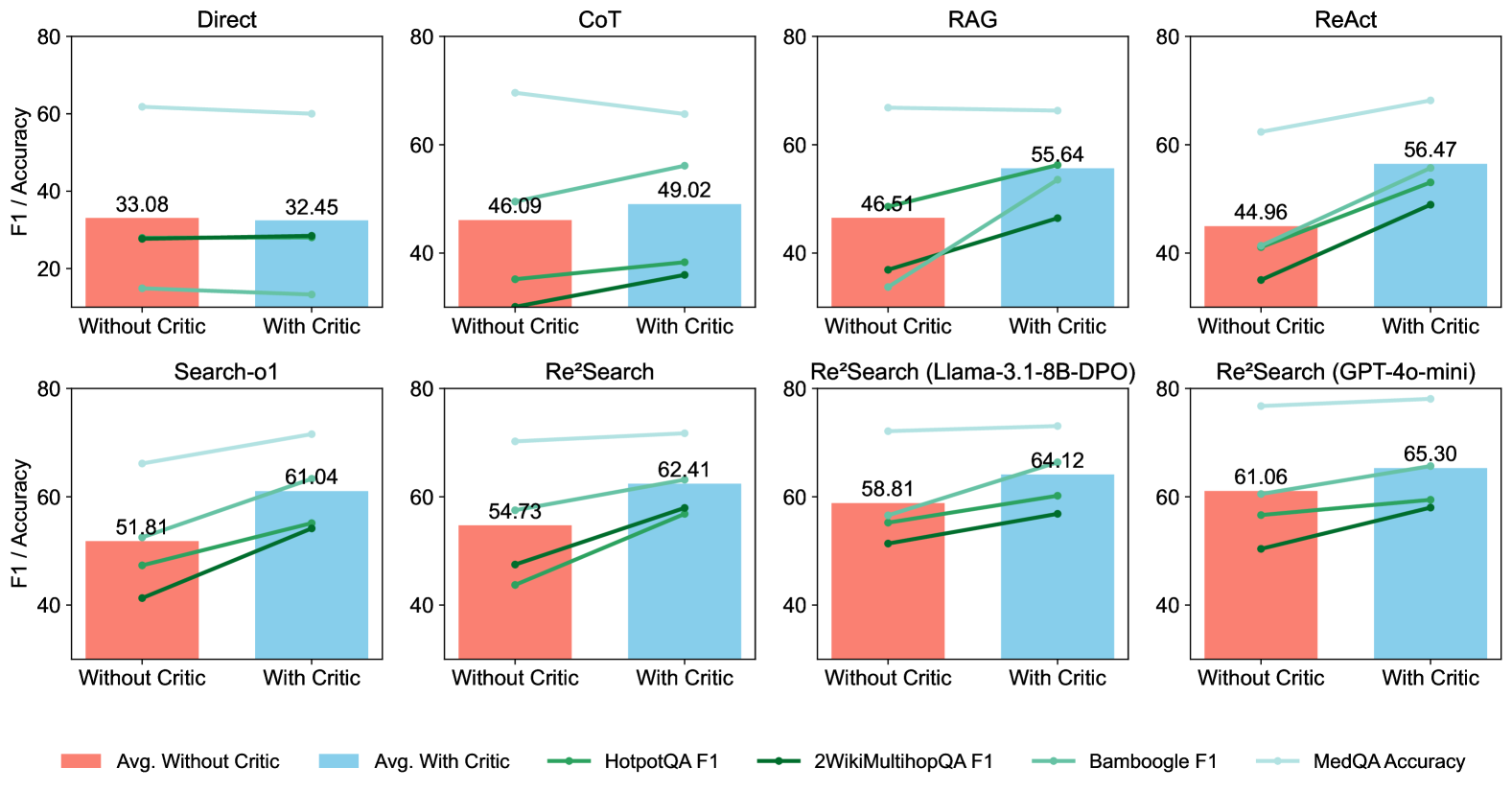
## Bar and Line Chart: Performance Comparison with and without Critic
### Overview
The image presents a series of bar and line charts comparing the performance of different models or methods ("Direct", "CoT", "RAG", "ReAct", "Search-o1", "Re²Search", "Re²Search (Llama-3.1-8B-DPO)", "Re²Search (GPT-4o-mini)") with and without a "Critic" component. The charts display F1 scores and accuracy metrics for various datasets (HotpotQA, 2WikiMultihopQA, Bamboogle, MedQA). The x-axis indicates "Without Critic" and "With Critic", while the y-axis represents "F1 / Accuracy".
### Components/Axes
* **Titles:** Each chart has a title indicating the model or method being evaluated (e.g., "Direct", "CoT", "RAG", "ReAct", "Search-o1", "Re²Search", "Re²Search (Llama-3.1-8B-DPO)", "Re²Search (GPT-4o-mini)").
* **X-axis:** Categorical axis with two categories: "Without Critic" and "With Critic".
* **Y-axis:** Numerical axis labeled "F1 / Accuracy", ranging from 0 to 80.
* **Bars:** Represent the average F1/Accuracy "Without Critic" (coral color) and "With Critic" (light blue color).
* **Lines:** Represent F1/Accuracy scores for different datasets:
* HotpotQA F1 (green)
* 2WikiMultihopQA F1 (dark green)
* Bamboogle F1 (light green)
* MedQA Accuracy (light blue)
* **Legend:** Located at the bottom of the image, associating colors with data series:
* Coral: Avg. Without Critic
* Light Blue: Avg. With Critic
* Green: HotpotQA F1
* Dark Green: 2WikiMultihopQA F1
* Light Green: Bamboogle F1
* Light Blue: MedQA Accuracy
### Detailed Analysis
**Chart 1: Direct**
* Avg. Without Critic: 33.08
* Avg. With Critic: 32.45
* HotpotQA F1: 27.5 to 27.5 (approximately equal)
* Bamboogle F1: 61.5 to 59.5 (approximately equal)
**Chart 2: CoT**
* Avg. Without Critic: 46.09
* Avg. With Critic: 49.02
* HotpotQA F1: 35 to 37
* 2WikiMultihopQA F1: 30 to 32
* Bamboogle F1: 69 to 66
**Chart 3: RAG**
* Avg. Without Critic: 46.51
* Avg. With Critic: 55.64
* HotpotQA F1: 40 to 48
* 2WikiMultihopQA F1: 27 to 50
* Bamboogle F1: 67 to 67 (approximately equal)
**Chart 4: ReAct**
* Avg. Without Critic: 44.96
* Avg. With Critic: 56.47
* HotpotQA F1: 39 to 50
* 2WikiMultihopQA F1: 42 to 52
* Bamboogle F1: 63 to 65
**Chart 5: Search-o1**
* Avg. Without Critic: 51.81
* Avg. With Critic: 61.04
* HotpotQA F1: 41 to 54
* 2WikiMultihopQA F1: 47 to 55
* Bamboogle F1: 67 to 70
**Chart 6: Re²Search**
* Avg. Without Critic: 54.73
* Avg. With Critic: 62.41
* HotpotQA F1: 46 to 58
* 2WikiMultihopQA F1: 48 to 59
* Bamboogle F1: 70 to 72
**Chart 7: Re²Search (Llama-3.1-8B-DPO)**
* Avg. Without Critic: 58.81
* Avg. With Critic: 64.12
* HotpotQA F1: 52 to 59
* 2WikiMultihopQA F1: 54 to 60
* Bamboogle F1: 72 to 74
**Chart 8: Re²Search (GPT-4o-mini)**
* Avg. Without Critic: 61.06
* Avg. With Critic: 65.30
* HotpotQA F1: 56 to 59
* 2WikiMultihopQA F1: 57 to 60
* Bamboogle F1: 74 to 76
### Key Observations
* In most cases, the "With Critic" configuration results in a higher average F1/Accuracy compared to "Without Critic". The "Direct" method is an exception, where the "With Critic" performance is slightly lower.
* The Bamboogle F1 score is consistently higher than the HotpotQA and 2WikiMultihopQA F1 scores across all models/methods.
* The Re²Search methods (especially with Llama-3.1-8B-DPO and GPT-4o-mini) generally achieve higher average F1/Accuracy scores compared to the other methods.
### Interpretation
The data suggests that incorporating a "Critic" component generally improves the performance of the models/methods evaluated, as indicated by the higher average F1/Accuracy scores in most cases. The "Direct" method is a notable exception, suggesting that the "Critic" component may not be beneficial or may even hinder performance in certain architectures. The consistently high Bamboogle F1 scores indicate that these models/methods perform well on the Bamboogle dataset. The Re²Search methods, particularly those using Llama-3.1-8B-DPO and GPT-4o-mini, appear to be the most effective overall, suggesting that the Re²Search approach combined with these language models yields superior results.