\n
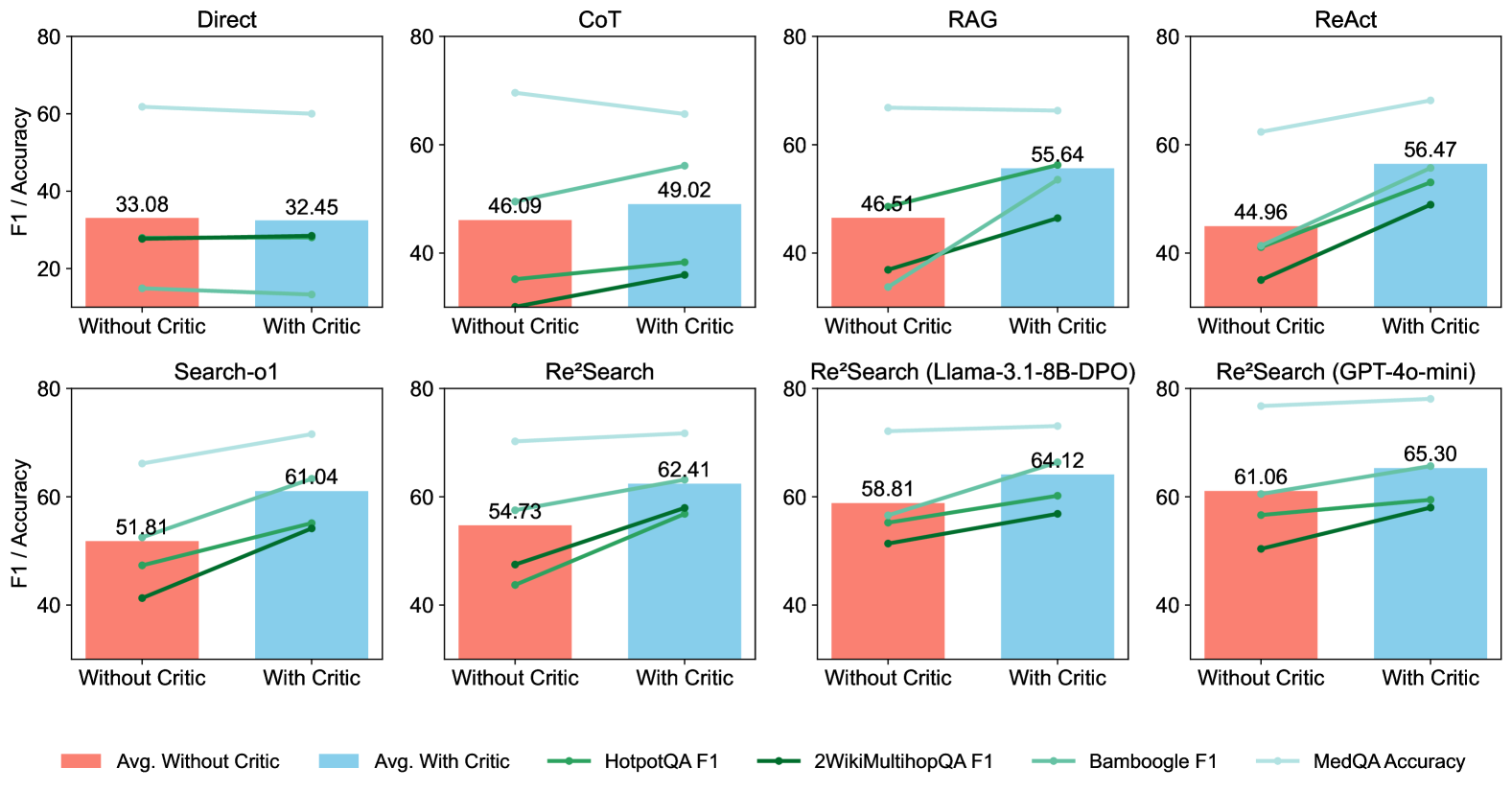
## Bar Chart with Line Overlays: Performance Comparison of Different Methods with and without Critic
### Overview
The image presents a series of bar charts, each representing the performance of a different method (Direct, CoT, RAG, ReAct, Search-01, ReSearch, Re²Search (Llama-3.1-8B-DPO), Re²Search (GPT-4o-mini)) on a task. Each method is evaluated twice: once "Without Critic" and once "With Critic". Performance is measured using F1 score and Accuracy, represented by bar heights and line trends respectively. The charts are arranged in a 2x4 grid.
### Components/Axes
* **Y-axis Label:** "F1 / Accuracy" (ranging from 0 to 80)
* **X-axis Labels:** "Without Critic", "With Critic"
* **Chart Titles:** "Direct", "CoT", "RAG", "ReAct", "Search-01", "ReSearch", "Re²Search (Llama-3.1-8B-DPO)", "Re²Search (GPT-4o-mini)"
* **Legend:**
* Avg. Without Critic (Peach/Light Orange)
* Avg. With Critic (Light Blue)
* HotpotQA F1 (Red)
* 2WikiMultihopQA F1 (Green)
* Bamboogle F1 (Blue)
* MedQA Accuracy (Purple)
### Detailed Analysis or Content Details
**1. Direct:**
* Avg. Without Critic: Approximately 33.08
* Avg. With Critic: Approximately 32.45
* HotpotQA F1: Line starts at ~20 and ends at ~25.
* 2WikiMultihopQA F1: Line starts at ~20 and ends at ~25.
* Bamboogle F1: Line starts at ~20 and ends at ~25.
* MedQA Accuracy: Line starts at ~20 and ends at ~25.
**2. CoT:**
* Avg. Without Critic: Approximately 46.09
* Avg. With Critic: Approximately 49.02
* HotpotQA F1: Line starts at ~35 and ends at ~40.
* 2WikiMultihopQA F1: Line starts at ~35 and ends at ~40.
* Bamboogle F1: Line starts at ~35 and ends at ~40.
* MedQA Accuracy: Line starts at ~35 and ends at ~40.
**3. RAG:**
* Avg. Without Critic: Approximately 46.61
* Avg. With Critic: Approximately 55.64
* HotpotQA F1: Line starts at ~35 and ends at ~45.
* 2WikiMultihopQA F1: Line starts at ~35 and ends at ~45.
* Bamboogle F1: Line starts at ~35 and ends at ~45.
* MedQA Accuracy: Line starts at ~35 and ends at ~45.
**4. ReAct:**
* Avg. Without Critic: Approximately 44.96
* Avg. With Critic: Approximately 56.47
* HotpotQA F1: Line starts at ~35 and ends at ~45.
* 2WikiMultihopQA F1: Line starts at ~35 and ends at ~45.
* Bamboogle F1: Line starts at ~35 and ends at ~45.
* MedQA Accuracy: Line starts at ~35 and ends at ~45.
**5. Search-01:**
* Avg. Without Critic: Approximately 51.81
* Avg. With Critic: Approximately 61.04
* HotpotQA F1: Line starts at ~40 and ends at ~50.
* 2WikiMultihopQA F1: Line starts at ~40 and ends at ~50.
* Bamboogle F1: Line starts at ~40 and ends at ~50.
* MedQA Accuracy: Line starts at ~40 and ends at ~50.
**6. ReSearch:**
* Avg. Without Critic: Approximately 54.73
* Avg. With Critic: Approximately 62.41
* HotpotQA F1: Line starts at ~40 and ends at ~50.
* 2WikiMultihopQA F1: Line starts at ~40 and ends at ~50.
* Bamboogle F1: Line starts at ~40 and ends at ~50.
* MedQA Accuracy: Line starts at ~40 and ends at ~50.
**7. Re²Search (Llama-3.1-8B-DPO):**
* Avg. Without Critic: Approximately 58.81
* Avg. With Critic: Approximately 64.12
* HotpotQA F1: Line starts at ~45 and ends at ~55.
* 2WikiMultihopQA F1: Line starts at ~45 and ends at ~55.
* Bamboogle F1: Line starts at ~45 and ends at ~55.
* MedQA Accuracy: Line starts at ~45 and ends at ~55.
**8. Re²Search (GPT-4o-mini):**
* Avg. Without Critic: Approximately 61.06
* Avg. With Critic: Approximately 65.30
* HotpotQA F1: Line starts at ~45 and ends at ~55.
* 2WikiMultihopQA F1: Line starts at ~45 and ends at ~55.
* Bamboogle F1: Line starts at ~45 and ends at ~55.
* MedQA Accuracy: Line starts at ~45 and ends at ~55.
In all charts, the lines representing the different F1 scores and accuracy metrics generally slope upwards from "Without Critic" to "With Critic", indicating an improvement in performance when using the "Critic" component.
### Key Observations
* The "Re²Search (GPT-4o-mini)" method consistently shows the highest average performance, both with and without the critic.
* The "Direct" method exhibits the lowest average performance.
* The performance improvement from "Without Critic" to "With Critic" is most pronounced in the RAG, ReAct, Search-01, ReSearch, Re²Search (Llama-3.1-8B-DPO), and Re²Search (GPT-4o-mini) methods.
* The lines representing the different metrics (HotpotQA F1, 2WikiMultihopQA F1, Bamboogle F1, MedQA Accuracy) are nearly identical within each chart, suggesting a consistent performance trend across these datasets.
### Interpretation
The data suggests that incorporating a "Critic" component generally improves the performance of various methods on the evaluated task. The magnitude of improvement varies depending on the method, with some methods (like Direct) showing minimal gains, while others (like RAG and ReAct) experience substantial improvements. The consistent upward trend of the lines indicates that the "Critic" is effectively refining the outputs of these methods. The superior performance of "Re²Search (GPT-4o-mini)" suggests that this method, combined with the "Critic", is particularly well-suited for the task. The near-identical trends of the different metrics within each chart imply that the "Critic" is improving performance across a range of datasets and evaluation criteria. This could indicate that the "Critic" is addressing fundamental issues in the reasoning or generation process, rather than being specific to a particular dataset.