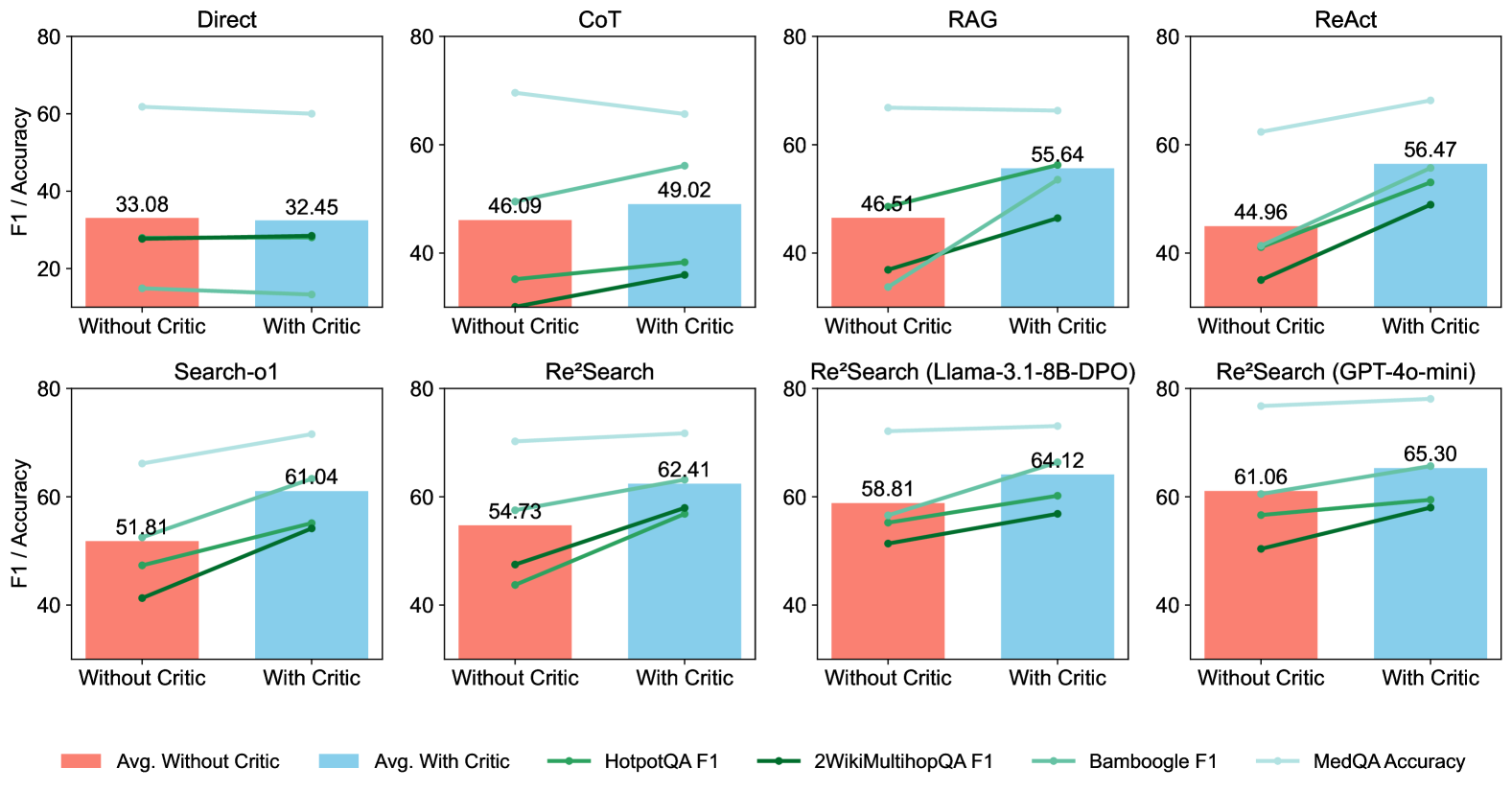
\n
## Bar Charts with Line Overlays: Performance Comparison of AI Reasoning Methods With and Without a Critic
### Overview
The image displays a 2x4 grid of eight bar charts. Each chart compares the performance of a specific AI reasoning method (e.g., Direct, CoT, RAG) under two conditions: "Without Critic" and "With Critic". Performance is measured on a y-axis labeled "F1 / Accuracy" (scale 0-80). Each chart contains two bars representing the average performance and four overlaid lines representing performance on specific benchmark datasets. A legend at the bottom defines all visual elements.
### Components/Axes
* **Chart Titles (Top of each subplot):** Direct, CoT, RAG, ReAct, Search-o1, Re²Search, Re²Search (Llama-3.1-8B-DPO), Re²Search (GPT-4o-mini).
* **Y-Axis (All charts):** Label: "F1 / Accuracy". Scale: 0, 20, 40, 60, 80.
* **X-Axis (All charts):** Two categorical labels: "Without Critic" (left), "With Critic" (right).
* **Legend (Bottom of image, spanning full width):**
* **Bars:**
* Red Square: "Avg. Without Critic"
* Blue Square: "Avg. With Critic"
* **Lines (with markers):**
* Medium Green Line with Circle Marker: "HotpotQA F1"
* Dark Green Line with Circle Marker: "2WikiMultihopQA F1"
* Teal Line with Circle Marker: "Bamboogle F1"
* Light Blue Line with Circle Marker: "MedQA Accuracy"
### Detailed Analysis
**Chart 1: Direct**
* **Bars:** Avg. Without Critic = 33.08, Avg. With Critic = 32.45. A slight decrease.
* **Lines:** All four lines show a slight downward or flat trend from "Without" to "With" Critic. MedQA Accuracy (light blue) is the highest line, starting ~62 and ending ~60.
**Chart 2: CoT (Chain-of-Thought)**
* **Bars:** Avg. Without Critic = 46.09, Avg. With Critic = 49.02. An increase.
* **Lines:** All four lines show an upward trend. MedQA Accuracy (light blue) is highest, starting ~70 and ending ~65 (a slight decrease, unlike the others).
**Chart 3: RAG (Retrieval-Augmented Generation)**
* **Bars:** Avg. Without Critic = 46.51, Avg. With Critic = 55.64. A significant increase.
* **Lines:** All four lines show a strong upward trend. The Bamboogle F1 (teal) line shows the steepest increase.
**Chart 4: ReAct**
* **Bars:** Avg. Without Critic = 44.96, Avg. With Critic = 56.47. A very significant increase.
* **Lines:** All four lines show a strong upward trend. The HotpotQA F1 (medium green) line shows a particularly steep slope.
**Chart 5: Search-o1**
* **Bars:** Avg. Without Critic = 51.81, Avg. With Critic = 61.04. A significant increase.
* **Lines:** All four lines show a strong upward trend. The MedQA Accuracy (light blue) line starts ~66 and ends ~72.
**Chart 6: Re²Search**
* **Bars:** Avg. Without Critic = 54.73, Avg. With Critic = 62.41. An increase.
* **Lines:** All four lines show an upward trend. The MedQA Accuracy (light blue) line is highest, starting ~70 and ending ~72.
**Chart 7: Re²Search (Llama-3.1-8B-DPO)**
* **Bars:** Avg. Without Critic = 58.81, Avg. With Critic = 64.12. An increase.
* **Lines:** All four lines show an upward trend. The MedQA Accuracy (light blue) line is highest, starting ~72 and ending ~74.
**Chart 8: Re²Search (GPT-4o-mini)**
* **Bars:** Avg. Without Critic = 61.06, Avg. With Critic = 65.30. An increase.
* **Lines:** All four lines show an upward trend. The MedQA Accuracy (light blue) line is highest, starting ~77 and ending ~79.
### Key Observations
1. **Universal Benefit of Critic:** In 7 out of 8 methods (all except "Direct"), both the average score and the scores on all four individual benchmarks improve when the "Critic" is added.
2. **Magnitude of Improvement:** The performance gain from adding a critic is most pronounced for the ReAct and RAG methods (increases of ~11.5 and ~9.1 points in average score, respectively).
3. **Benchmark Hierarchy:** The MedQA Accuracy (light blue line) is consistently the highest-performing metric across all methods and conditions, followed typically by Bamboogle F1 (teal). HotpotQA and 2WikiMultihopQA F1 scores are generally lower.
4. **Method Performance:** The Re²Search variants, especially the GPT-4o-mini version, achieve the highest absolute scores, with averages exceeding 60 both with and without the critic.
5. **Direct Method Anomaly:** The "Direct" method is the only one where adding a critic leads to a slight decrease in average performance and shows no improvement on the individual benchmarks.
### Interpretation
This data strongly suggests that integrating a "Critic" module—a system that reviews or refines an initial answer—is a highly effective strategy for improving the performance of complex AI reasoning tasks across multiple methodologies. The consistent upward trends in the line graphs for benchmarks like HotpotQA and 2WikiMultihopQA, which require multi-hop reasoning, indicate the critic is particularly helpful for verifying and correcting logical steps.
The stark contrast between the "Direct" method (no improvement) and all others implies the critic's value is contingent on the underlying reasoning process being sufficiently structured (like in CoT, RAG, or search-based methods) for it to evaluate and enhance. The "Direct" approach may lack the intermediate steps a critic needs to operate effectively.
Furthermore, the progression from simpler methods (Direct, CoT) to more advanced search and iterative methods (Search-o1, Re²Search) shows a rising baseline of performance. The fact that these advanced methods also benefit significantly from a critic indicates that even sophisticated reasoning pipelines have room for improvement through external verification, pushing the state-of-the-art higher, as seen with the Re²Search (GPT-4o-mini) results approaching 80% accuracy on MedQA.