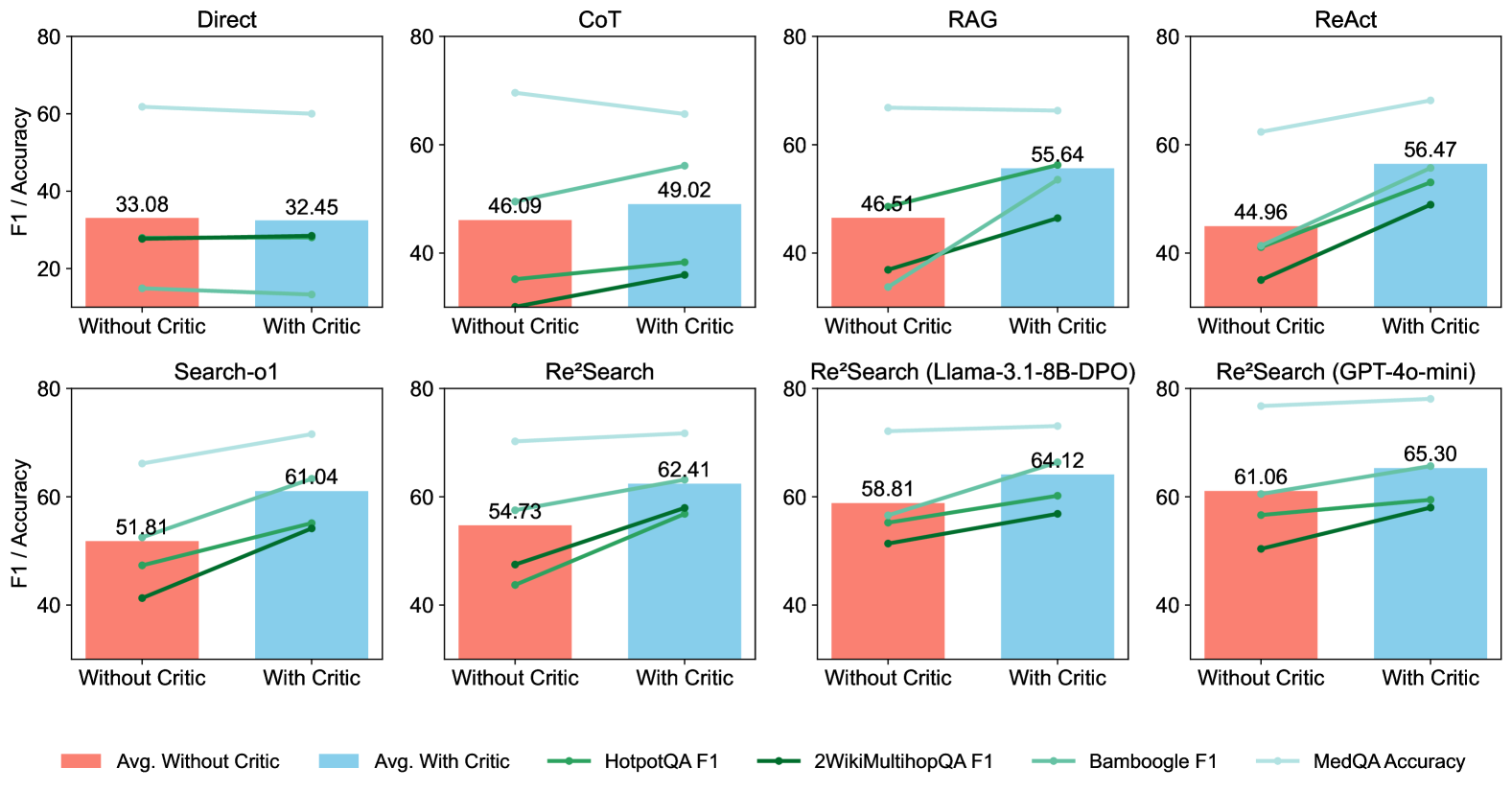
## Bar Chart: Comparative Performance of Methods with/Without Critic
### Overview
The image presents a grouped bar chart comparing the performance of six different methods (Direct, CoT, RAG, ReAct, Search-o1, Re²Search) with and without a critic. Each sub-chart includes:
- Two bars: "Avg. Without Critic" (orange) and "Avg. With Critic" (blue)
- Four lines representing datasets: HotpotQA F1 (green), 2WikiMultihopQA F1 (dark green), Bamboo F1 (light green), and MedQA Accuracy (light blue)
### Components/Axes
- **X-axis**: "Without Critic" (left) and "With Critic" (right)
- **Y-axis**: F1/Accuracy (0-80 scale)
- **Legend**: Located at the bottom, with six entries:
1. Avg. Without Critic (orange)
2. Avg. With Critic (blue)
3. HotpotQA F1 (green line)
4. 2WikiMultihopQA F1 (dark green line)
5. Bamboo F1 (light green line)
6. MedQA Accuracy (light blue line)
### Detailed Analysis
#### Direct Method
- **Bars**:
- Without Critic: 33.08 (orange)
- With Critic: 32.45 (blue)
- **Lines**:
- HotpotQA F1: ~25 (green)
- 2WikiMultihopQA F1: ~27 (dark green)
- Bamboo F1: ~15 (light green)
- MedQA Accuracy: ~60 (light blue)
#### CoT Method
- **Bars**:
- Without Critic: 46.09 (orange)
- With Critic: 49.02 (blue)
- **Lines**:
- HotpotQA F1: ~35 (green)
- 2WikiMultihopQA F1: ~37 (dark green)
- Bamboo F1: ~30 (light green)
- MedQA Accuracy: ~65 (light blue)
#### RAG Method
- **Bars**:
- Without Critic: 46.51 (orange)
- With Critic: 55.64 (blue)
- **Lines**:
- HotpotQA F1: ~40 (green)
- 2WikiMultihopQA F1: ~45 (dark green)
- Bamboo F1: ~50 (light green)
- MedQA Accuracy: ~60 (light blue)
#### ReAct Method
- **Bars**:
- Without Critic: 44.96 (orange)
- With Critic: 56.47 (blue)
- **Lines**:
- HotpotQA F1: ~45 (green)
- 2WikiMultihopQA F1: ~50 (dark green)
- Bamboo F1: ~55 (light green)
- MedQA Accuracy: ~65 (light blue)
#### Search-o1 Method
- **Bars**:
- Without Critic: 51.81 (orange)
- With Critic: 61.04 (blue)
- **Lines**:
- HotpotQA F1: ~50 (green)
- 2WikiMultihopQA F1: ~55 (dark green)
- Bamboo F1: ~60 (light green)
- MedQA Accuracy: ~70 (light blue)
#### Re²Search Method
- **Bars**:
- Without Critic: 58.81 (orange)
- With Critic: 64.12 (blue)
- **Lines**:
- HotpotQA F1: ~60 (green)
- 2WikiMultihopQA F1: ~62 (dark green)
- Bamboo F1: ~64 (light green)
- MedQA Accuracy: ~75 (light blue)
### Key Observations
1. **Critic Impact**:
- "With Critic" bars generally show higher values than "Without Critic" in most methods (e.g., ReAct: +11.51, Re²Search: +5.31).
- Exceptions: Direct method shows a slight decrease (-0.63) with critic.
2. **Dataset Performance**:
- MedQA Accuracy consistently outperforms other datasets across all methods (60-75 range).
- HotpotQA F1 and 2WikiMultihopQA F1 show similar trends, with 2WikiMultihopQA F1 slightly higher in most cases.
3. **Method-Specific Trends**:
- ReAct and Re²Search demonstrate the largest performance gains with critic integration.
- Search-o1 shows the highest absolute improvement (+9.23) with critic.
### Interpretation
The data suggests that critic integration generally enhances performance across methods, with the most significant gains observed in ReAct (+11.51) and Re²Search (+5.31). The consistent dominance of MedQA Accuracy (60-75 range) indicates it may represent a specialized or optimized metric. The Direct method's slight decline with critic integration (-0.63) warrants further investigation into potential overfitting or method-specific limitations. The strong correlation between critic use and improved performance in complex methods (ReAct, Re²Search) implies that critical evaluation mechanisms are particularly effective for sophisticated reasoning tasks.