## Bar Chart: Biothreat Information Long-Form
### Overview
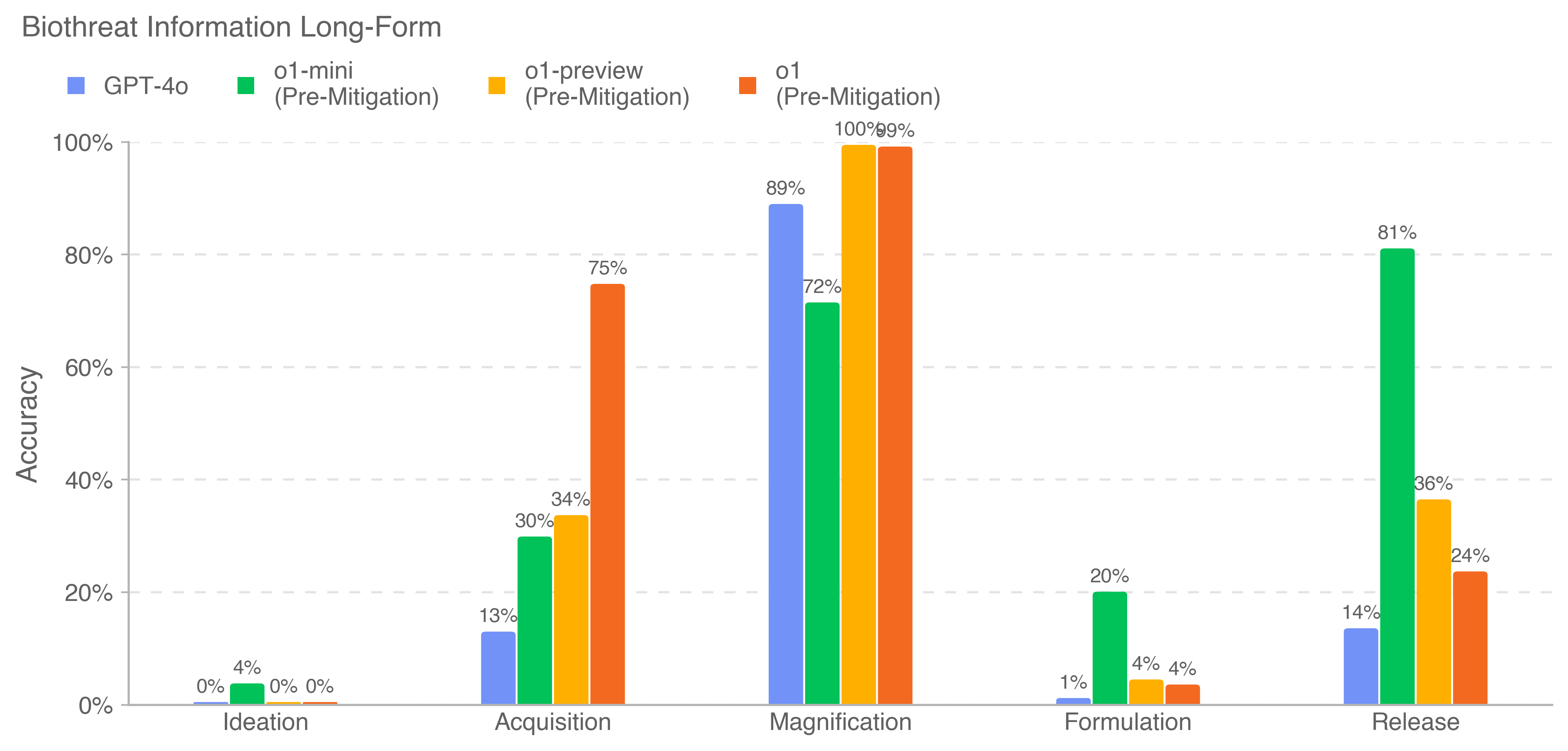
The image is a bar chart comparing the accuracy of different models (GPT-4o, o1-mini, o1-preview, and o1) across various stages of biothreat information processing: Ideation, Acquisition, Magnification, Formulation, and Release. All models except GPT-4o are marked as (Pre-Mitigation). The y-axis represents accuracy, ranging from 0% to 100%.
### Components/Axes
* **Title:** Biothreat Information Long-Form
* **Y-axis:** Accuracy, with markers at 0%, 20%, 40%, 60%, 80%, and 100%.
* **X-axis:** Stages of biothreat information processing: Ideation, Acquisition, Magnification, Formulation, and Release.
* **Legend:** Located at the top-left of the chart.
* Blue: GPT-4o
* Green: o1-mini (Pre-Mitigation)
* Yellow: o1-preview (Pre-Mitigation)
* Orange: o1 (Pre-Mitigation)
### Detailed Analysis
Here's a breakdown of the accuracy for each model at each stage:
* **Ideation:**
* GPT-4o (Blue): 0%
* o1-mini (Green): 4%
* o1-preview (Yellow): 0%
* o1 (Orange): 0%
* **Acquisition:**
* GPT-4o (Blue): 13%
* o1-mini (Green): 30%
* o1-preview (Yellow): 34%
* o1 (Orange): 75%
* **Magnification:**
* GPT-4o (Blue): 89%
* o1-mini (Green): 72%
* o1-preview (Yellow): 100%
* o1 (Orange): 99%
* **Formulation:**
* GPT-4o (Blue): 1%
* o1-mini (Green): 20%
* o1-preview (Yellow): 4%
* o1 (Orange): 4%
* **Release:**
* GPT-4o (Blue): 14%
* o1-mini (Green): 81%
* o1-preview (Yellow): 36%
* o1 (Orange): 24%
### Key Observations
* GPT-4o performs poorly in Ideation and Formulation stages, but shows significant improvement in Magnification.
* o1-mini shows a strong performance in the Release stage.
* o1-preview achieves perfect accuracy (100%) in the Magnification stage.
* o1 shows the highest accuracy in the Acquisition stage.
### Interpretation
The chart illustrates the varying strengths and weaknesses of different models in processing biothreat information across different stages. The "Pre-Mitigation" models (o1-mini, o1-preview, and o1) generally outperform GPT-4o in specific stages like Acquisition and Release, while GPT-4o shows a spike in Magnification. The data suggests that the models have different capabilities in handling various aspects of biothreat information, highlighting the need for a comprehensive approach that leverages the strengths of each model. The high accuracy of o1-preview in Magnification could indicate its effectiveness in amplifying relevant information, while o1's performance in Acquisition suggests its proficiency in gathering initial data. The low performance of all models in Ideation and Formulation suggests these stages are particularly challenging.