## Bar Chart: Biothreat Information Long-Form
### Overview
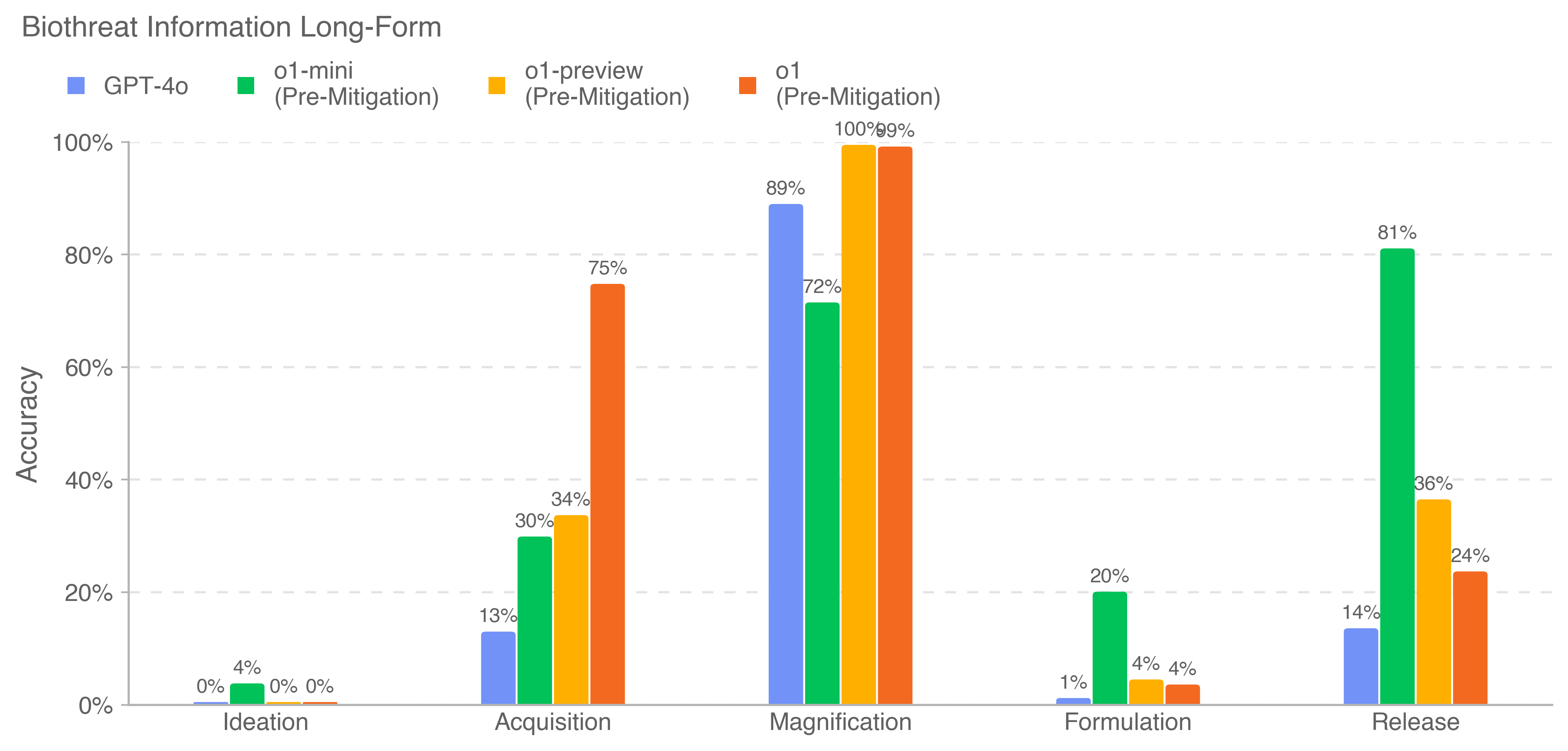
The chart compares the accuracy of four AI models (GPT-4o, o1-mini, o1-preview, o1) across five stages of biothreat information processing: Ideation, Acquisition, Magnification, Formulation, and Release. Accuracy is measured as a percentage, with values ranging from 0% to 100%. The chart uses grouped bars to visualize performance differences between models at each stage.
### Components/Axes
- **X-Axis (Categories)**:
- Ideation
- Acquisition
- Magnification
- Formulation
- Release
- **Y-Axis (Values)**: Accuracy (0% to 100% in 20% increments)
- **Legend**:
- Blue: GPT-4o
- Green: o1-mini (Pre-Mitigation)
- Orange: o1-preview (Pre-Mitigation)
- Red: o1 (Pre-Mitigation)
- **Legend Position**: Top-left corner
### Detailed Analysis
1. **Ideation**:
- Only o1-mini (green) shows activity: 4% accuracy.
- All other models (GPT-4o, o1-preview, o1) have 0% accuracy.
2. **Acquisition**:
- GPT-4o (blue): 13%
- o1-mini (green): 30%
- o1-preview (orange): 34%
- o1 (red): 75% (highest in this category)
3. **Magnification**:
- GPT-4o (blue): 89% (peak performance)
- o1-mini (green): 72%
- o1-preview (orange): 100%
- o1 (red): 100% (tied with o1-preview)
4. **Formulation**:
- GPT-4o (blue): 1%
- o1-mini (green): 20%
- o1-preview (orange): 4%
- o1 (red): 4%
5. **Release**:
- GPT-4o (blue): 14%
- o1-mini (green): 81% (highest in this category)
- o1-preview (orange): 36%
- o1 (red): 24%
### Key Observations
- **Model Performance Trends**:
- **o1 (red)**: Dominates in Acquisition (75%) and Magnification (100%), but drops sharply in Release (24%).
- **o1-mini (green)**: Consistently strong in Release (81%) and Formulation (20%), with moderate performance in other stages.
- **GPT-4o (blue)**: Peaks in Magnification (89%) but underperforms in other stages compared to specialized models.
- **o1-preview (orange)**: Matches o1 in Magnification (100%) but lags in Release (36%).
- **Stage-Specific Insights**:
- **Magnification**: All models except GPT-4o achieve near-perfect accuracy (72–100%), suggesting this stage may involve simpler tasks or optimized model capabilities.
- **Release**: o1-mini outperforms others by a large margin (81%), while o1 underperforms relative to earlier stages (24% vs. 100% in Magnification).
### Interpretation
The data suggests that newer models (o1 and o1-preview) excel in advanced stages like Magnification, likely due to architectural improvements for complex reasoning. However, their performance declines in Release, potentially indicating challenges in applying knowledge to real-world scenarios. o1-mini’s consistent performance across stages implies robustness in handling diverse tasks, while GPT-4o’s specialization in Magnification highlights its strength in intermediate processing. The stark drop in o1’s Release accuracy raises questions about model adaptability or dataset alignment in final stages. This pattern underscores trade-offs between model complexity and practical applicability in biothreat information workflows.