## Diagram: Fine-Tuning Language Model
### Overview
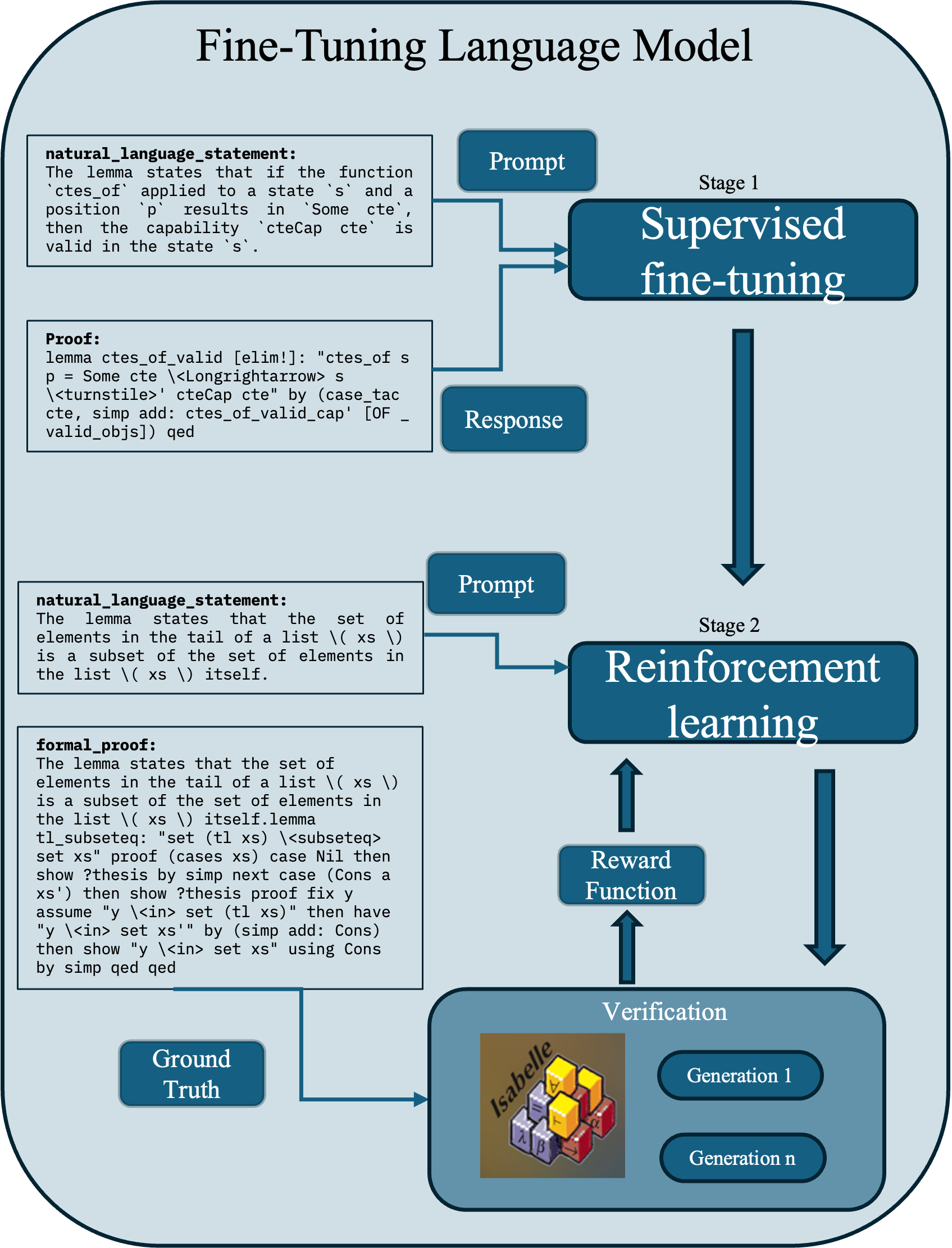
The image is a flowchart illustrating the process of fine-tuning a language model. It depicts two main stages: Supervised fine-tuning and Reinforcement learning, along with the inputs, outputs, and verification steps involved in each stage.
### Components/Axes
* **Title:** Fine-Tuning Language Model
* **Stage 1:** Supervised fine-tuning
* Input: Prompt (from a text box containing a natural language statement and a proof)
* Output: Response
* **Stage 2:** Reinforcement learning
* Input: Prompt (from a text box containing a natural language statement and a formal proof)
* Reward Function
* **Verification:**
* Isabelle (image of a stack of blocks with mathematical symbols)
* Generation 1
* Generation n
* **Ground Truth:** (from a text box)
### Detailed Analysis
The diagram starts with two blocks of text on the left side. The top block contains a "natural_language_statement" and a "Proof". The natural language statement reads: "The lemma states that if the function `ctes_of` applied to a state 's' and a position `p` results in `Some cte`, then the capability `cteCap cte` is valid in the state `s`." The proof is a formal statement: "lemma ctes_of_valid [elim!]: "ctes_of s p = Some cte \<Longrightarrow> s \<turnstile>' cteCap cte" by (case_tac cte, simp add: ctes_of_valid_cap' [OF - valid_objs]) qed".
A "Prompt" box feeds into "Stage 1: Supervised fine-tuning". The output of this stage is a "Response".
The second block of text on the left side contains another "natural_language_statement" and a "formal_proof". The natural language statement reads: "The lemma states that the set of elements in the tail of a list \( xs \) is a subset of the set of elements in the list \( xs \) itself." The formal proof reads: "The lemma states that the set of elements in the tail of a list \( xs \) is a subset of the set of elements in the list \( xs \) itself.lemma tl_subseteq: "set (tl xs) \<subseteq> set xs" proof (cases xs) case Nil then show ?thesis by simp next case (Cons a xs') then show ?thesis proof fix y assume "y \<in> set (tl xs)" then have "y \<in> set xs'" by (simp add: Cons) then show "y \<in> set xs" using Cons by simp qed qed".
A "Prompt" box feeds into "Stage 2: Reinforcement learning". A "Reward Function" also feeds into this stage.
The output of "Stage 2: Reinforcement learning" feeds into "Verification", which contains an image labeled "Isabelle" and two "Generation" boxes ("Generation 1" and "Generation n"). A "Ground Truth" box also feeds into the "Verification" stage.
### Key Observations
* The diagram illustrates a two-stage fine-tuning process.
* Each stage uses a prompt, but the content of the prompt differs (natural language statement + proof vs. natural language statement + formal proof).
* Reinforcement learning incorporates a reward function.
* The verification stage uses Isabelle and multiple generations.
### Interpretation
The diagram outlines a process for fine-tuning a language model, starting with supervised learning and progressing to reinforcement learning. The inclusion of formal proofs in the second stage suggests a focus on ensuring the model's reasoning and outputs are logically sound. The verification stage, using Isabelle (a proof assistant), indicates a rigorous approach to validating the model's performance and correctness. The "Ground Truth" input to the verification stage suggests a comparison against known correct answers or behaviors. The diagram highlights the iterative nature of the process, with multiple generations being evaluated during verification.